「MIR-06」打破砂锅问到底,不同python库做音频预处理的区别在哪里?
音频预处理通常是将原始波形处理为时频谱,即各种spectrograms,这一步可使用librosa或essentia,涉及到深度学习模型也可直接用torchaudio或tensorflow。但即使输入同个音频,采用同样的参数,得出的时频谱还是有细微差别。
-
通用参数的解释与设置 -
得出的spectrogram的区别 -
得出的mel filter bank的区别 -
得出的mel spectrogram的区别
『通用参数设置』
-
librosa: version 0.8.1
-
essentia: version 2.1b6.dev374 -
torchaudio: version 0.9.0, with torch 1.9.0 -
tensorflow: version 2.6.0
每个库中对音频预处理的默认参数不同,所以我们需要统一一下。鉴于tensorflow中可改的选项最不灵活,所以参数设置都向它对齐 (比如,tensorflow从linear到mel尺度进行转换时,依赖Hidden Markov Model Toolkit (HTK),所以需统一NORM设置为None,且MEL_SCALE设置为'htk')。
下表列出我们统一设定的参数值,以及几个库中的参数名和默认值 (若有):
| 参数值统一设定为 |
librosa默认值 |
torchaudio默认值 |
tensorflow默认值 |
|---|---|---|---|
| SAMPLE_RATE=44100 | sr=22050 | sample_rate=16000 | sample_rate |
| N_FFT=2048 | n_fft=2048 | n_fft=400 |
fft_length=frame_length |
| HOP_LENGTH=512 | hop_length=512 |
hop_length=win_length//2 |
frame_step |
| WIN_LENGTH=N_FFT | win_length=n_fft | win_length=n_fft | frame_length |
| WINDOW='hann' | window='hann' |
window_fn= torch.hann_window
|
window_fn= tf.signal.hann_window |
| CENTER=False | center=True | center=True |
分帧无法center |
| PAD_END=False | pad_mode='reflect' | pad_mode='reflect' |
pad_end=False |
| F_MIN=0 | fmin=0.0 | f_min=0 | lower_edge_hertz |
|
F_MAX=SAMPLE_RATE/2 |
fmax=sr/2 | f_max=None | upper_edge_hertz |
| N_FREQS=N_FFT//2+1 | - | n_freqs | num_spectrogram_bins |
| N_MELS= 128 | n_mels=128 | n_mels=128 |
num_mel_bins
|
| NORM=None | norm='slaney' | norm=None |
依赖HTK |
| MEL_SCALE='htk' | htk=False | mel_scale='htk' | 依赖HTK |
本文中用到的事例音频可从librosa下载,并只用其40秒到45秒之间重采样的片段数据。
import numpy as npimport pandas as pdimport librosafrom essentia.standard import *import torch, torchaudioimport tensorflow as tffilename = librosa.util.example_audio_file()audio, _ = librosa.load(filename,sr=SAMPLE_RATE, mono=MONO,offset=OFFSET, duration=LOAD_DURATION)
『Spectrogram』
分别用四种不同的库,计算示例5秒音频片段的magnitue spectrogram和log
power spectrogram。
☞ 使用librosa得到的维度是1025 x 427:
# magnitude spectrogramspec_librosa = np.abs(librosa.stft(y=audio,n_fft=N_FFT,hop_length=HOP_LENGTH,win_length=WIN_LENGTH,window=WINDOW,center=CENTER))# log power spectrogramlpspec_librosa = librosa.power_to_db(spec_librosa ** 2)
☞ 使用essentia得到的维度是427 x 1025:
# magnitude spectrogramspec_essentia = []es_win_func = Windowing(normalized=False, size=WIN_LENGTH, type='hann')es_spec_func = FFT(size=N_FFT)for frame in FrameGenerator(audio, frameSize=N_FFT, hopSize=HOP_LENGTH,startFromZero=True, validFrameThresholdRatio=1.0, lastFrameToEndOfFile=False):spec_complex = es_spec_func(es_win_func(frame))spec_essentia.append(np.abs(spec_complex))spec_essentia = essentia.array(spec_essentia)# log power spectrogramlpspec_essentia = librosa.power_to_db(spec_essentia ** 2)
☞ 使用torchaudio得到的维度是1025 x 427:
# magnitude spectrogramspec_torch = torchaudio.transforms.Spectrogram(n_fft=N_FFT,win_length=WIN_LENGTH,hop_length=HOP_LENGTH,window_fn=torch.hann_window,power=None,center=CENTER,return_complex=True)(torch.Tensor(audio))spec_torch = spec_torch.numpy()spec_torch = np.abs(spec_torch)# log power spectrogramlpspec_torch = librosa.power_to_db(spec_torch ** 2)
☞ 使用tensorflow得到的维度是427 x 1025:
# magnitude spectrogramspec_tf = tf.abs(tf.signal.stft(signals=tf.convert_to_tensor(audio, dtype=tf.float32),frame_length=N_FFT,frame_step=HOP_LENGTH,fft_length=N_FFT,window_fn=tf.signal.hann_window,pad_end=PAD_END))spec_tf = spec_tf.numpy()# log power spectrogramlpspec_tf = librosa.power_to_db(spec_tf ** 2)
将以上代码得到的log power spectrogram都画出来,也不会看到非常明显的不同。但是在数值上确实都是有区别的,区别的大小我们可以用Mean Square Error (MSE) 衡量,值越大则区别越大。下方表格的区别从小到大排列,统一设定参数的情况下,librosa和torchaudio得出的log power spectrogram在数值上最为接近。
| kernel | compare_kernel | mse | |
|---|---|---|---|
| 0 | librosa | torchaudio | 1.153476e-09 |
| 1 | librosa | tensorflow | 9.368608e-07 |
| 2 | tensorflow | torchaudio | 9.407697e-07 |
| 3 | essentia | torchaudio | 2.041789e-04 |
| 4 | essentia | librosa | 2.042010e-04 |
| 5 | essentia | tensorflow | 2.050108e-04 |
『Mel Filter Bank』
鉴于上文中essentia与其他区别相对较大,之后我们主要检查其余三个python库之间的区别。为了得到melspectrogram,可将上文得到的"linear频带的spectrogram"与"可转换到mel尺度的矩阵"做矩阵乘法。所以这里我们先来看一下不同python库得到的linear to mel matrix。
☞ 使用librosa得到的维度是128 x 1025:
l2m_librosa = librosa.filters.mel(sr=SAMPLE_RATE,n_fft=N_FFT,n_mels=N_MELS,fmin=F_MIN,fmax=F_MAX,htk=MEL_SCALE=='htk',norm=NORM)
☞ 使用torchaudio得到的维度是1025 x 128:
l2m_torch = torchaudio.functional.create_fb_matrix(n_freqs=N_FREQS,f_min=F_MIN,f_max=F_MAX,n_mels=N_MELS,sample_rate=SAMPLE_RATE,norm=NORM,mel_scale=MEL_SCALE)
☞ 使用tensorflow得到的维度是1025 x 128:
l2m_tf = tf.signal.linear_to_mel_weight_matrix(num_mel_bins=N_MELS,num_spectrogram_bins=N_FREQS,sample_rate=SAMPLE_RATE,lower_edge_hertz=F_MIN,upper_edge_hertz=F_MAX)
以上三者之间的区别如下表所示,max_abs_diff表示,两两相减时得到的最大绝对差值。
| kernel | compare_kernel | max_abs_diff | mse | |
|---|---|---|---|---|
| 0 | librosa | torchaudio | 0.000011 | 2.611765e-13 |
| 1 | librosa | tensorflow | 0.003384 | 9.346046e-08 |
| 2 | tensorflow | torchaudio | 0.003392 | 9.356785e-08 |
依然是librosa和torchaudio之间差别最小。
『Mel Spectrogram』
最后得magnitude melspectrogram, power melspectrogram, log power melspectrogram三者,可按以下代码运算。
# librosamelspec_librosa = np.dot(l2m_librosa, spec_librosa)pmelspec_librosa = np.dot(l2m_librosa, spec_librosa ** 2)lpmelspec_librosa = librosa.power_to_db(pmelspec_librosa)# torchaudiomelspec_torch = torch.matmul(torch.Tensor(spec_torch.T), l2m_torch).numpy().Tpmelspec_torch = torch.matmul(torch.Tensor(spec_torch.T ** 2), l2m_torch).numpy().Tlpmelspec_torch = librosa.power_to_db(pmelspec_torch)# tensorflowmelspec_tf = tf.tensordot(spec_tf, l2m_tf, 1).numpy().Tpmelspec_tf = tf.tensordot(spec_tf ** 2, l2m_tf, 1).numpy().Tlpmelspec_tf = librosa.power_to_db(pmelspec_tf)
melspec_librosa和pmelspec_librosa,也可以直接通过librosa.feature.melspectrogram()输入audio或spec_librosa得到,需要注意其中相应power参数值的设定。
同理,torchaudio中也有直接得melspectrogram的功能:
pmelspec_torch_by_audio = torchaudio.transforms.MelSpectrogram(sample_rate=SAMPLE_RATE,n_fft=N_FFT,win_length=WIN_LENGTH,hop_length=HOP_LENGTH,f_min=F_MIN,f_max=F_MAX,n_mels=N_MELS,window_fn=torch.hann_window,power=2.0,normalized=False,center=CENTER,norm=NORM,mel_scale=MEL_SCALE)(torch.Tensor(audio))pmelspec_torch_by_audio = pmelspec_torch_by_audio.numpy()lpmelspec_torch_by_audio = librosa.power_to_db(pmelspec_torch_by_audio)
可是,目前我得到的pmelspec_torch_by_audio和前文中的pmelspec_torch,在数值上非常接近,但并非完全一致。
对以上log power melspectrogram之间的区别用MSE衡量可得:
| kernel | compare_kernel | mse | |
|---|---|---|---|
| 0 | librosa | torchaudio_l2m | 7.132773e-10 |
| 1 | librosa | torchaudio_direct | 7.133121e-10 |
| 2 | librosa | tensorflow | 1.559776e-04 |
| 3 | torchaudio_direct | torchaudio_l2m | 1.416461e-13 |
| 4 | tensorflow | torchaudio_l2m | 1.560096e-04 |
| 5 | tensorflow | torchaudio_direct | 1.560096e-04 |
画出最小 (librosa vs. torchaudio_l2m) 和最大 (tensorflow vs. torchaudio_direct) 对应在log power melspectrogram上的差值:
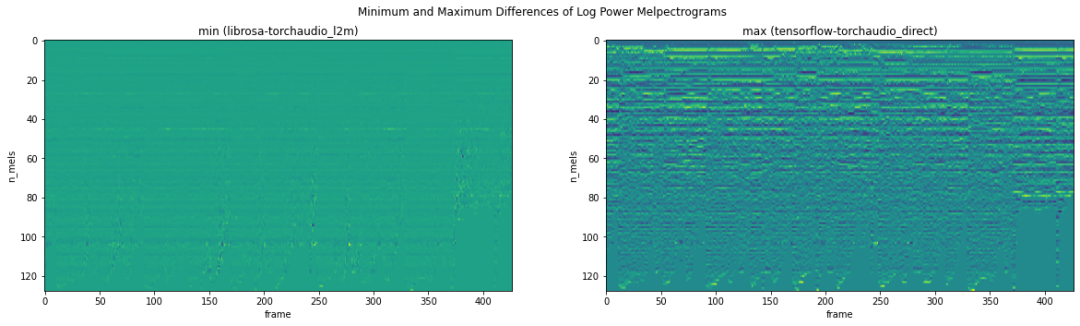
目前来看,librosa (0.8.0版本) 和torchaudio (0.9.0版本) 在参数设置相互对齐的前提下,可以得到数值上相对接近的音频预处理结果。最后强调一些引起数值差别的主要参数:
-
加窗时即使都使用'hann',但不同库的窗函数仍在数值上有细微差别;
-
分帧时是否居中 (center),若采用居中则还需注意数据填充的模式 (pad_mode);
-
设置mel尺度时,根据HTK还是Slaney公式 (mel_scale),另外要注意对mel权重的归一化方式 (norm)。