「INFO」从数据角度聊聊音乐版权版税
一个音乐人清楚自己的音乐作品和录音制品有哪些版权 (copyright),才能清楚之后会收入哪些版税 (royalty)。即使知道这些“基础知识”,存在于音乐产业各个链条中的数据问题,还是不可避免地导致版权和版税的折损。那么问题到底出在哪里?
博主去年从“面向听众”的腾讯音乐离职后,搬到了挪威并加入了一家“面向创作者”的音乐初创。因为同事们都是音乐制作出版发行的背景,就跟着学了不少行业知识,同时也从技术角度观察到音乐数据中尤其是元数据
(metadata)
的问题。当涉及到不同国家地区之间不同音乐版权版税规则下的数据置换,数据问题就更加复杂和严重,导致版税无法给到相应的音乐人,比如2021年仅在北美地区就有4亿多美元的音乐版税被搁置。为了把数据问题说明白,这篇文章主要会科普以下内容:
-
音乐作品和录音制品的区别
-
版权版税和相应机构的简介
-
音乐数据中的问题
『音乐作品vs录音制品』
当我们提到一首歌,会涉及到两个概念:音乐作品 (musical work or song) 和录音制品 (sound recording or master),这两者会有相应的版权,再由不同机构分别收集版税,即版权使用费。音乐作品包括作曲家创作的旋律、作词家写的歌词等等,录音制品则是由歌手等人表演并录制作品、混音和母带制作后得到的最终录音,可能有不同版本的录音被发行 (比如伴奏版、remaster版等等)。因此一个音乐作品可对应到多个录音制品。
音乐作品可以经由出版商 (publisher) 在其所在地区的著作权收集协会 (collection society) 注册,得到代表该作品的ISWC编号 (International Standard Musical Work Code)。录音制品则是通过唱片公司 (record label) 或发行商 (distributor) 注册,得到代表该录音的ISRC编号 (International Standard Recording Code)。一个ISWC可关联到多个ISRC。
至此我们可以理解内容平台开发类似YouTube的Content ID系统的必要性:比如在用户上传的内容中,找到其所用音乐对应的录音ISRC和作品ISWC。用音频指纹可以识别到特定的录音,版税收入就能给到这个录音对应的歌手等人,以及这个录音关联到的音乐作品的创作人。如果用户没使用音乐录音而是上传了一首自己的翻唱,则需要用到更复杂的翻唱识别算法找到相似的录音和关联的作品,版税收入就只分配到创作人一方。当然如果音乐作品和录音制品的版权压根就没有授予其他人,Content ID一旦检测到,就应该下架这个用户上传的内容。
上面的例子简单涉及到版权和版税内容,实际情况要复杂的多,下面就以在互联网上听歌为例说一说。
『版权版税和相应机构』
复杂首先体现在不同国家地区的音乐版权不同,其次是不同版权对应的版税由不同机构负责收集,最后是收集到的版税要分配给不同的人。这里借用MLC上的图,简单讲一下北美地区互联网上使用音乐时涉及的版权版税和相应机构 (博主注:下文里涉及的一些术语,因为不知道准确的中文翻译,就直接写英文了)。
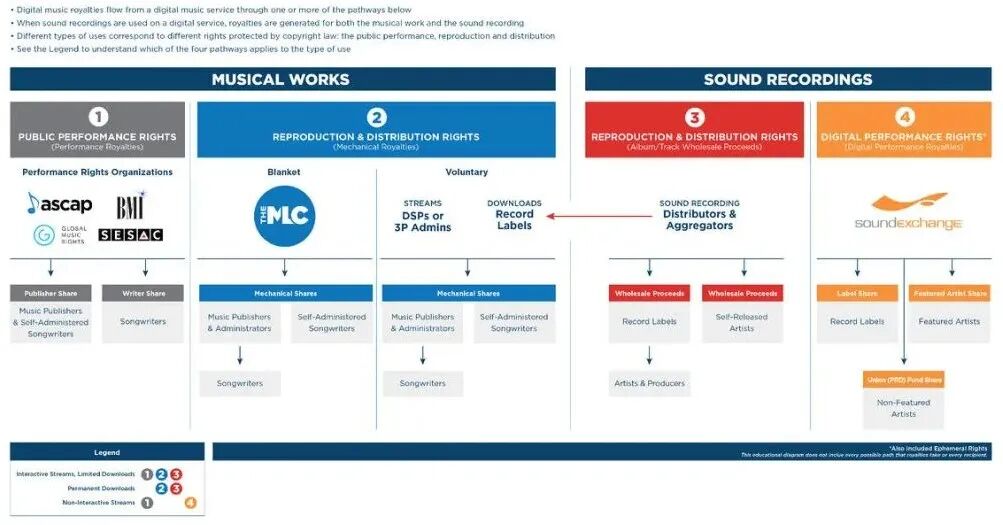
☞ 图源:https://www.themlc.com/digital-music-royalties-landscape
-
音乐作品的版权之public performance rights,相应的performance royalty版税会通过北美的著作权收集协会 (比如ascap、BMI、SESAC等,取决于作品当时注册在哪一个) 来收集,再按作品注册时声明的出版商和创作人之间的比例来分配版税; -
音乐作品的版权之reproduction and distribution rights,相应的mechanical royalty版税要不由MLC机构来收集,要不由音乐作品关联的录音制品所在发行商来收集 (如果事先有签订好合同),然后分配给出版商和创作人; -
录音制品的版权之reproduction and distribution rights,相应的版税即歌曲销量收入由发行商收集后,分配给唱片公司和歌手等人。
如果用户在数字平台上特意买了一首歌下载后不受限地听,即permanent
download,那只涉及上文ii和iii这两种版权版税。如果歌曲在电台类的数字平台上播放
(比如Pandora),用户不能自主选择,歌曲中的音乐作品涉及i中的版权版税,而录音制品则涉及digital
performance
rights,相应的版税由soundexchange机构收集后,按事先规定好的比例分配给唱片公司和歌手等人。
无论是哪种方式,录音制品相关的版税收入,因为数字平台和发行商之间能直接沟通,收入大多能准确地分配到唱片公司和歌手手里。但音乐作品相关的版税收入,由于要经由不同国家地区的著作权收集协会分别收集,此外还要通过出版商,作词作曲人的收入既不及时也不准确。再加上下一部分提到的数据问题,只能说创作人赚点钱好难!
『音乐数据中的问题』
以上文i中涉及的情况为例 (音乐作品的public performance rights),某个流媒体平台会将北美地区各个录音制品的收听记录发给北美地区的某个著作权收集协会,由该协会负责识别记录中的录音制品应该对应到注册在该协会下的哪个音乐作品,以此确定版税。最理想的情况是,记录中录音制品的ISRC都有关联的ISWC,就能直接定位到音乐作品,同时在该作品的注册记录下,每个创作人都有IPI或ISNI编号,那么版权收入就能准确地分发给创作人。可惜实际情况却是:
-
录音制品没有关联到音乐作品,需要通过录音制品的歌曲标题、歌手等元数据匹配到音乐作品,完成ISRC和ISWC之间的关联;
-
即使定位到了音乐作品,但因为该作品的注册记录下有缺失数据,无法准确识别相应的创作人。比如缺少IPI或ISNI编号时,提到英国摇滚乐队的鼓手Roger Taylor,也许是Queen的Roger (Meddows) Taylor,也有可能是Duran Duran的Roger (Andrew) Taylor。
著作权收集协会在关联ISRC和ISWC时,使用的技术目前还停留在基于文本的匹配,另外元数据本身还有大大小小的问题,所以第一步就卡住了。更不用提收集不同国家地区产生的版税时,仅由不同语言之间的文本翻译带来的识别问题
(比如弄混姓和名的前后顺序)。A$AP
Rocky他也许永远不知道,本意想赚更多$而起的名字,在各种系统的不同字符编码之间做匹配后,会少赚多少…
✎ 下面链接里的博客里有更多奇奇怪怪的音乐数据例子:https://dustri.org/b/horrible-edge-cases-to-consider-when-dealing-with-music.html
最后,如果你是一个全能音乐人,既作曲又唱歌,从音乐作品到录音制品都能办,那么记住以下几件事,保证你的音乐收益:
-
确保音乐作品和录音制品两个层面里元数据的准确,除了歌曲名字等数据,你也要有ISNI等表示“你是你”的身份编号 (ISNI是近年较通用可以表示各种身份的编号,IPI主要表示作曲/作词/出版商等音乐作品相关的人,IPN主要表示歌手/乐手/制作人等录音制品相关的人)。
-
作为作曲/作词等音乐作品相关人,成为你所在地区著作权收集协会的会员,当你创作了一首新的音乐作品,将其注册在该协会并得到作品的ISWC编号。一般是通过出版商完成注册,出版方也负责作品在其他地区协会的注册。
-
作为歌手/制作人等录音制品相关人,通过唱片公司或发行商使录音能在各个平台收听。该录音的数据中,既要有代表其本身的ISRC编号,也要和对应的音乐作品ISWC相关联。
在不同的国家地区,也许还要注册一些其他的协会才能全方位地回收各种版税。无论如何,音乐人要尤其注意源头数据的准确,否则错误的数据进入到接下来的音乐产业链条中,再改就既麻烦又缓慢,直接折损音乐人应得的版税收入。已有的匹配识别错误想要得到纠正,除了用更先进的自然语言处理算法甚至图模型,音频数据的加入也是一条解决路线。多模态的音乐信息检索技术,已经落地到不少流媒体平台做搜广推业务,希望之后也能成为真正帮助到音乐创作者的技术 :)