「MIR-05_1」音乐流派自动识别的前世今生
世界上有那么多新歌老歌,但各种歌曲之间总能被一些共性联系起来,“流派”就是共性之一。那我们能否通过MIR技术,直接依据音频自动识别出一首歌曲是民谣、乡村、爵士、摇滚、电音…还是哪种流派呢?
-
什么是音乐流派? -
近20年来流派识别发展到什么水平? -
主要的挑战和未来的方向?
『音乐流派』
根据《音频音乐与计算机的交融——音频音乐技术》第13章“音乐分类”中提到的定义:音乐的流派或风格常用来描述音乐家及其音乐作品的相似性,传达音乐偏好和品味,并用来组织音乐曲目,是文化、艺术家和音乐市场之间相互影响的产物。
大多数人谈论音乐流派时,一般指的是现当代流行文化下的流派,与此同时,不同人对不同流派间的界限感知也是模糊的,对于人脑来说“流派检测”都是一项偏主观的任务,更不用说依赖MIR技术直接从音频中自动识别了。
鉴于音乐流派的确切定义还涉及许多音乐专业知识,与其我在这儿长篇大论,不如一图胜千言:
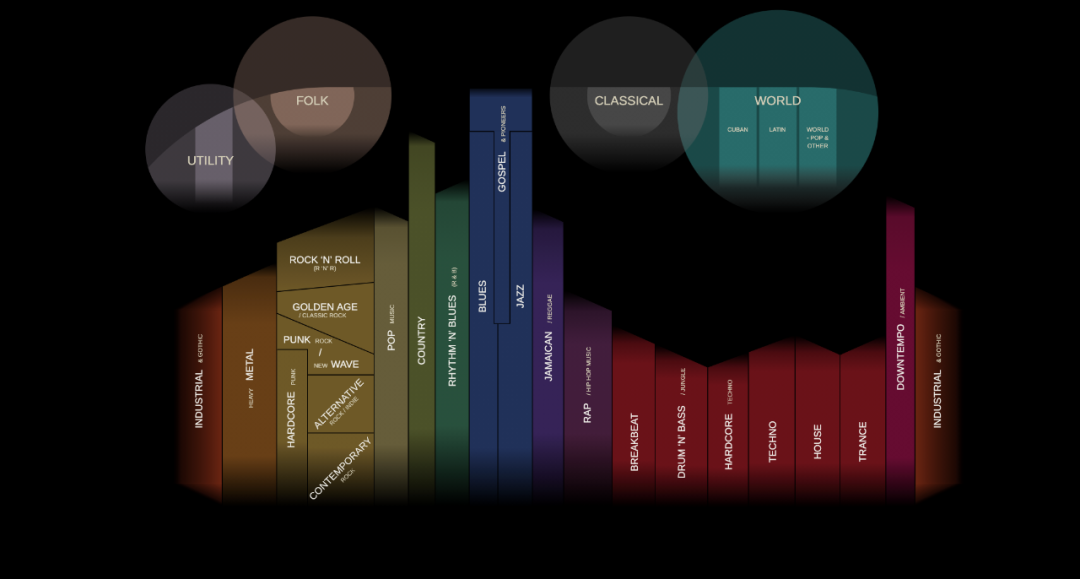 以上截图来源于我最爱的可以交互式认识音乐流派的网站musicmap.info,图片中圆圈/长方条出现的位置表示该流派出现的时间早晚,比如最上方的四大圆圈都是世界上较早出现的音乐流派/类型(utility主要指带某种功能的音乐比如宗教音乐,folk主要指传统民谣,classical就是古典音乐了,world泛指世界各地的民族音乐),下面五颜六色的长方条就是大家更熟悉的流行音乐流派,颜色越相近,流派越相似。
以上截图来源于我最爱的可以交互式认识音乐流派的网站musicmap.info,图片中圆圈/长方条出现的位置表示该流派出现的时间早晚,比如最上方的四大圆圈都是世界上较早出现的音乐流派/类型(utility主要指带某种功能的音乐比如宗教音乐,folk主要指传统民谣,classical就是古典音乐了,world泛指世界各地的民族音乐),下面五颜六色的长方条就是大家更熟悉的流行音乐流派,颜色越相近,流派越相似。
如果流派之间真的就像上图那样分立,那事情就简单得多了,然而我们放大图片后看到的事实是这样的:
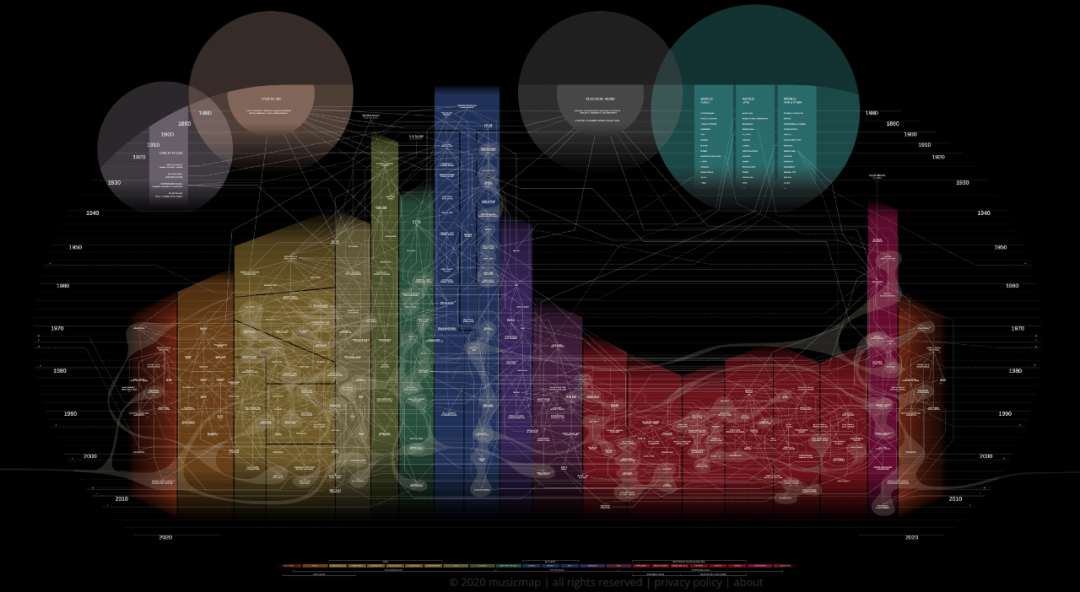
能理清不同流派之间的关系,本身就是门复杂的taxonomy/ontology大学问了,在everynoise.com网站上,Spotify的工程师Glenn Mcdonald更是把平台上能“搜刮”到的流派通通通通列了出来。
『流派识别』
所以,当我们谈论“音乐流派的自动识别” (Music Genre Recognition, 即MGR) 的时候,到底在谈论什么?这要取决于面对的音乐样本大体在哪个范围,以及到底要识别成哪些流派的类。
学术界里大多受制于音乐数据集,自动识别就变成了一个分类任务。比如,当我们采用被广泛使用的GTZAN数据集时,MGR任务就是将集内的歌曲
(其实是30秒的片段) 识别为规定好的十大流派之一。
截止到2012年年末,已经有500余篇论文研究MGR算法,基于音乐音频做识别占大多数,且大部分采用特征工程的策略,即先对音频进行预处理提取特征,再训练分类模型进行流派识别。鉴于属于同一流派的音乐之间,总会在音色、和声、节奏等方面相似,因此提取的音频特征大多对应以上三种。
✎ 以上特征工程相关论文的大调查,可参考文献: Sturm, Bob L. "A survey of evaluation in music genre recognition." International Workshop on Adaptive Multimedia Retrieval. Springer, Cham, 2012..
然而,音频特征对应到音色等方面时,就已经自带了一层“语义隔阂” (比如说从MFCC的系数变化中,你真的能理解到这是个什么音色么?),再从中去提取更高的语义信息“流派”,真的会有效么?当然,可以不断地去叠加各种特征,增加模型的训练参数,甚至实现“端到端”从无到有硬生生的学出来。
此时此刻这种策略,大家应该都能get到吧?没错,深度学习的时代来临了。这里的标杆进展,可以直接搬出三位老朋友的名字,大家搜他们的google scholar或个人主页就好(此处并没有“其他人的工作就没啥亮点了”的意思,以下三位确实是连文章带代码都清清楚楚的):
☞ Keunwoo
Choi:首先将图像领域火起来的CNN、CRNN等模型运用到音乐音频分类任务中
(下图a)
☞ Jordi Pons:改良CNN的前/中/后端,结合音乐先验知识进行各种实验,并已将训练好的musicnn模型集成到Essentia中,开源的榜样!(下图b)
☞ Jongpil Lee:和以上两位工作里“基于音频的时频谱做输入”不同,直接采用音频的波形,从sample-level搞事情 (下图c)

鉴于以上深度学习的模型,依赖的环境和评估用的数据集有不同,所以UPF的Minz Won小哥将他们都复现到pytorch中,并和自己的算法 (上图d) 做了详细比较,发表在今年的SMC上:
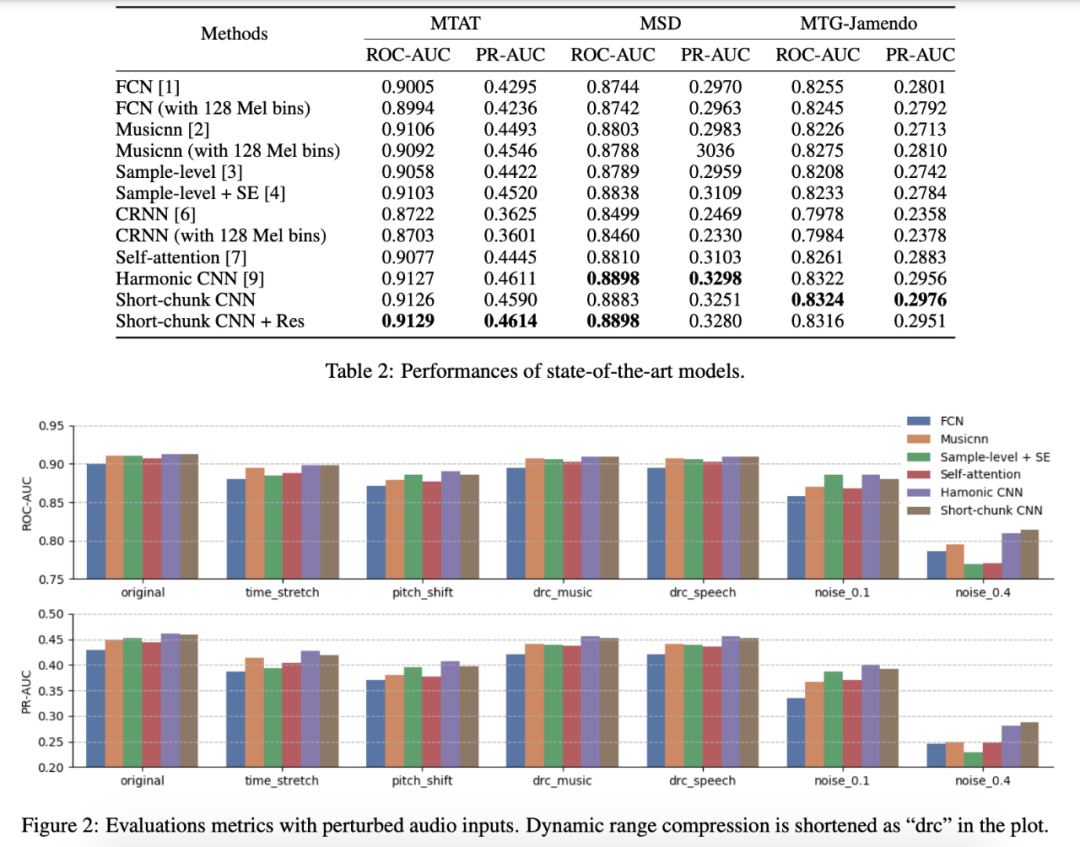
✎ 以上截图来源自文献: Won, Minz, et al. "Evaluation of CNN-based Automatic Music Tagging Models." arXiv preprint arXiv:2006.00751 (2020).
☞ 代码可见:
https://github.com/minzwon/sota-music-tagging-models/
『挑战与未来』
虽然大量音频数据+深度学习帮助流派识别任务又迈了一大步,但其在工业界的大规模落地还是任重道远。
鉴于受过音乐训练的人,听了3秒左右的音乐就能判别出音乐的大类流派 (且准确率>70%),目前训练模型时也都采用3秒到30秒不等的秒级输入。但是当我们真的想准确描述一首歌的流派时,需要考虑整首。片段级的结果如何映射为整曲级?是否要考虑不同结构化片段的权重 (比如是否要更看重副歌段落下的检测结果)?
模型的输出结果,和“标准答案”不一致时,就真的错了么?即使号召了20位音乐专业人士对一些曲子进行标注,流派结果依然众说纷纭(参考2017年Palmason等人的论文Music Genre Classification Revisited: An In-Depth Examination Guided by Music Experts)。如果判别流派自动标注的性能需要beyond accuracy,那什么是合适的新指标?
如果基于音频的自动流派识别只能停留在对大类流派标签的输出,怎样活用其他信息比如歌曲歌词、专辑封面等等,提升某些流派的识别能力?另外,能否用其中间结果搭建embedding,辅助其他音乐相关的任务 (比如解决新歌推荐冷启动)?
在真正面对千万级曲库时,如何结合音乐知识,让已有算法迅速对流派标签查缺补漏,而不是只能停留在模型底层的开发?(正所谓用假模假式的fancy模型,掩盖模型开发者本身对音乐知识的欠缺…这个锅,不懂音乐的产品经理也有份)
所以说,做MIR还是离不开音乐本乐。否则,即使某天发现了一个识别算法好似万金油,实际却是the famous horse "Clever Hans"。
✎ 上面一句话的典故来自文献: Sturm, Bob L. "A simple method to determine if a music information retrieval system is a “horse”." IEEE Transactions on Multimedia 16.6 (2014): 1636-1644.
最后,秉着无痛入门的原则,读者想自己搭建一个流派分类模型,但电脑又不带高端的GPU资源的话,不妨先尝试下“迁移学习” (transfer learning)!