评估#
可靠地评估音乐描述系统是一项具有挑战性的工作。即使我们有”真实标注”的字幕,如何对生成的文本进行评分也并不总是明确的,因为音乐描述是开放式的,且至少在一定程度上是主观的。描述的质量也很大程度上取决于其使用的具体场景。对于 MQA 或其他基于指令的描述等更加对话化的任务,这一问题更加突出。 将模型输出与静态数据集中的标准答案进行比较是有帮助的,但这只是第一步。
总体而言,当前的评估策略通常是基于参考的自动指标评估和人工评估的混合,同时还包括为评估语言生成而设计的新协议。下面我们详细介绍自动评估方法。
基于匹配的指标#
字幕生成系统自动评估的一种常见方法依赖于度量生成字幕与一组参考字幕之间句法或语义相似度的指标。这些指标借鉴自计算机视觉和自然语言处理领域的文献,最初是为评估机器翻译(BLEU、METEOR、ROUGE)、图像字幕生成(CIDEr、SPICE、SPIDEr)或其他文本生成任务(BERT-Score)中的文本输出而创建的。正如我们将看到的,将它们用于评估 music captioning 并非没有问题,但它们继续被用于客观评估,因为它们提供了一种方便的方式来将生成的文本与参考字幕进行比较。
下面我们简要回顾每个指标:
BLEU 通过取基于 \(n\)-gram 精确率 \(P_n\) 的几何平均值来衡量候选字幕与真实标注字幕之间的相似度,可以仅使用 unigram(BLEU_1),也可以使用最多到 4-gram 的组合(BLEU\textsubscript{4})。最终分数的计算还包括一个简短惩罚项,用于在整体层面上惩罚与参考文本长度不匹配的候选文本。
METEOR 同样衡量生成字幕与参考字幕之间的相似度,但通过将一个 \(F\)-score(unigram 精确率 \(P_1\) 和召回率 \(R_1\) 的调和平均值)与一个惩罚项相结合来实现——该惩罚项根据候选文本与参考文本之间匹配的较长 \(n\)-gram 数量来降低分数。
ROUGE 通常用于文本摘要,同样基于生成文本与真实标注文本之间重叠单元匹配计算的 F-score。根据所考虑单元的长度,该指标有不同的变体。其中,我们采用 ROUGE\textsubscript{L},它考虑的是最长公共子序列的匹配,而非使用预定义的 \(n\)-gram 长度。
CIDEr 旨在通过衡量候选字幕与大多数参考字幕的匹配程度来捕捉人类共识。具体做法是对候选文本和参考文本的 tf-idf 加权 \(n\)-gram 之间的平均余弦相似度求和(通常 \(n=\{1, 2, 3, 4\}\)),相较于基于匹配的指标,在图像字幕生成中与人类判断具有更好的相关性。
SPICE 基于场景图(scene graph)的语义相似度比较,场景图是从候选字幕和参考字幕中解析出的对象及其关系的表示。这些表示在很大程度上抽象掉了字幕的词法和句法特征,而是聚焦于文本中语义有意义的成分。
SPIDEr 是 SPICE 和 CIDEr 的线性组合。
BERT-Score 同样计算生成句子中的 token 与真实标注文本中 token 之间的相似度,但使用预训练 BERT 模型获得的上下文 embedding 而非精确匹配,从而与人类判断具有更高的相关性。
局限性#
虽然这些指标是评估模型在较为封闭任务上输出的一个有用起点,但它们无法捕捉音乐描述中所有可接受的变化。例如,对于一首音乐作品,可能有多个同样合理的字幕,但它们在句法或语义相似度方面几乎没有共同之处。在音乐领域和通用音频描述等其他领域,许多研究都强调了这些指标的重要局限性,例如它们无法考虑字幕中合理的变化,也无法与人类判断保持一致 [LL24]。因此,纳入人工评估和特定任务的基准测试对于实现更全面的评估是必要的。
基准测试#
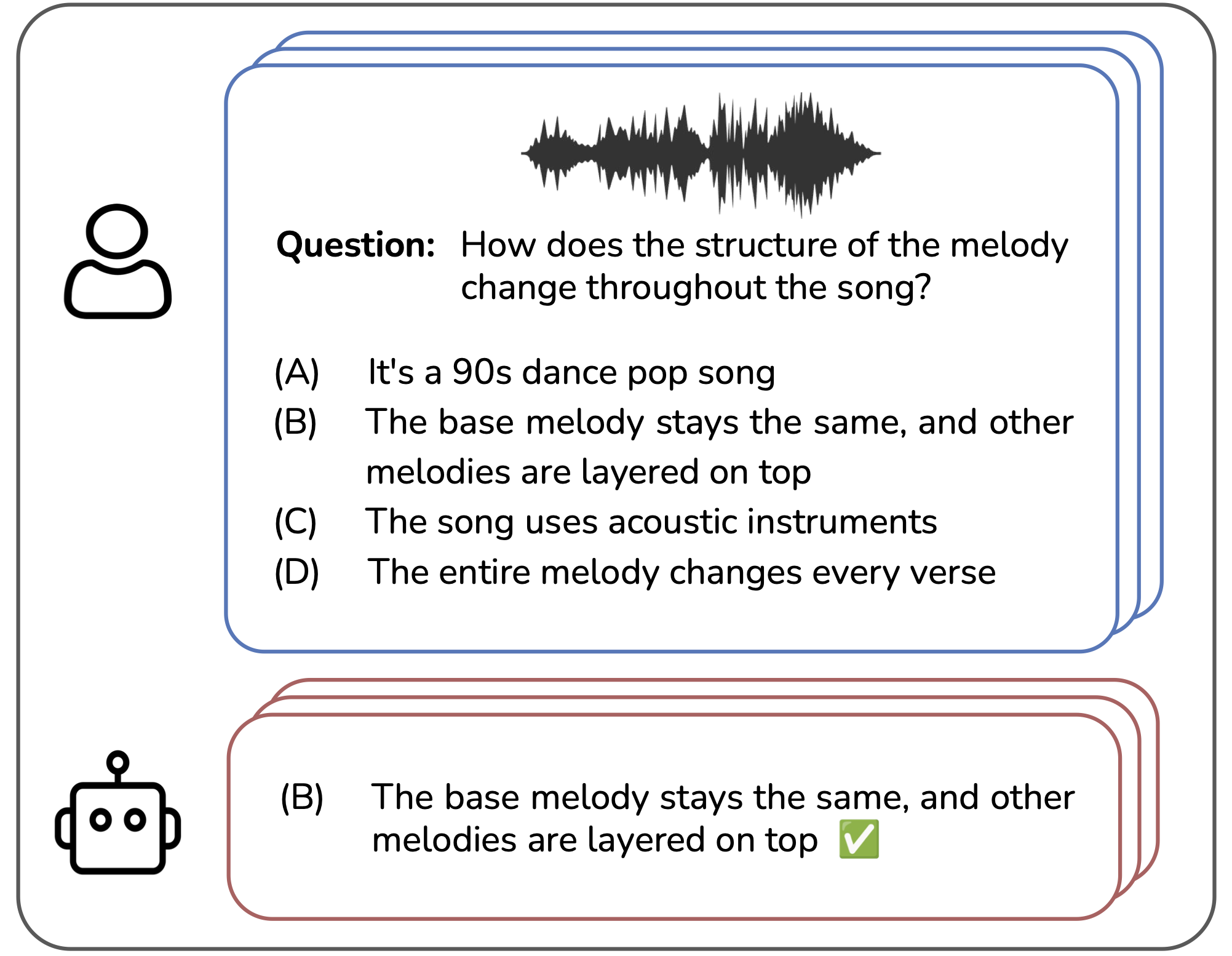
为了克服基于匹配的指标的一些不足,最近出现了一些基准测试,旨在通过多选问答来评估音乐理解或描述能力。这些基准测试也更适合近期音乐描述系统的对话格式,因为它们侧重于评估对特定用户提示(问题)的回复。一些此类基准测试面向通用音频-语言评估设计,并将音乐作为更广泛领域的一部分。其中包括 AudioBench [WZL+24] 和 AIR-Bench [YXL+24]。其他的基准测试,包括 MuChoMusic [WMB+24] 和 OpenMU [ZZM+24],则直接聚焦于音乐:
参考文献#
Jinwoo Lee and Kyogu Lee. Do captioning metrics reflect music semantic alignment? In International Society for Music Information Retrieval (ISMIR) 2024, Late Breaking Demo (LBD). 2024. URL: https://arxiv.org/abs/2411.11692.
Bin Wang, Xunlong Zou, Geyu Lin, Shuo Sun, Zhuohan Liu, Wenyu Zhang, Zhengyuan Liu, AiTi Aw, and Nancy F Chen. Audiobench: a universal benchmark for audio large language models. arXiv preprint arXiv:2406.16020, 2024.
Benno Weck, Ilaria Manco, Emmanouil Benetos, Elio Quinton, George Fazekas, and Dmitry Bogdanov. MuChoMusic: Evaluating Music Understanding in Multimodal Audio-Language Models. In 25th International Society for Music Information Retrieval Conference. August 2024. arXiv:2408.01337 [cs, eess]. URL: http://arxiv.org/abs/2408.01337 (visited on 2024-08-21), doi:10.48550/arXiv.2408.01337.
Qian Yang, Jin Xu, Wenrui Liu, Yunfei Chu, Ziyue Jiang, Xiaohuan Zhou, Yichong Leng, Yuanjun Lv, Zhou Zhao, Chang Zhou, and Jingren Zhou. AIR-bench: benchmarking large audio-language models via generative comprehension. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1979–1998. Bangkok, Thailand, August 2024. Association for Computational Linguistics. URL: https://aclanthology.org/2024.acl-long.109, doi:10.18653/v1/2024.acl-long.109.
Mengjie Zhao, Zhi Zhong, Zhuoyuan Mao, Shiqi Yang, Wei-Hsiang Liao, Shusuke Takahashi, Hiromi Wakaki, and Yuki Mitsufuji. OpenMU: Your Swiss Army Knife for Music Understanding. October 2024. arXiv:2410.15573. URL: http://arxiv.org/abs/2410.15573 (visited on 2024-11-09).