连接音乐音频与自然语言#
Note
此中文版由 Claude Code 翻译,存储于 intro2musictech 仓库。英文原版请参见 mulab-mir/music-language-tutorial。
欢迎来到”连接音乐音频与自然语言”教程的在线补充材料。本教程于2024年11月10日至14日在美国旧金山举行的第25届国际音乐信息检索学会(ISMIR)会议上呈现。本电子书包含教程中展示的所有内容,包括代码示例、参考文献以及深入探讨相关主题的补充材料。
动机与目标#
语言是人与人之间以及人与机器之间高效沟通的接口。随着近年来基于深度学习的预训练语言模型的快速发展,对音乐的理解、搜索和创作已经能够以多样性和精确性满足用户偏好。本教程的动机源于机器学习技术的快速进步,特别是在语言模型领域及其在音乐信息检索(MIR)领域不断增长的应用。语言模型理解和生成类人文本的卓越能力,为音乐描述、检索和生成开辟了创新方法论,预示着我们通过技术与音乐互动方式的新时代。
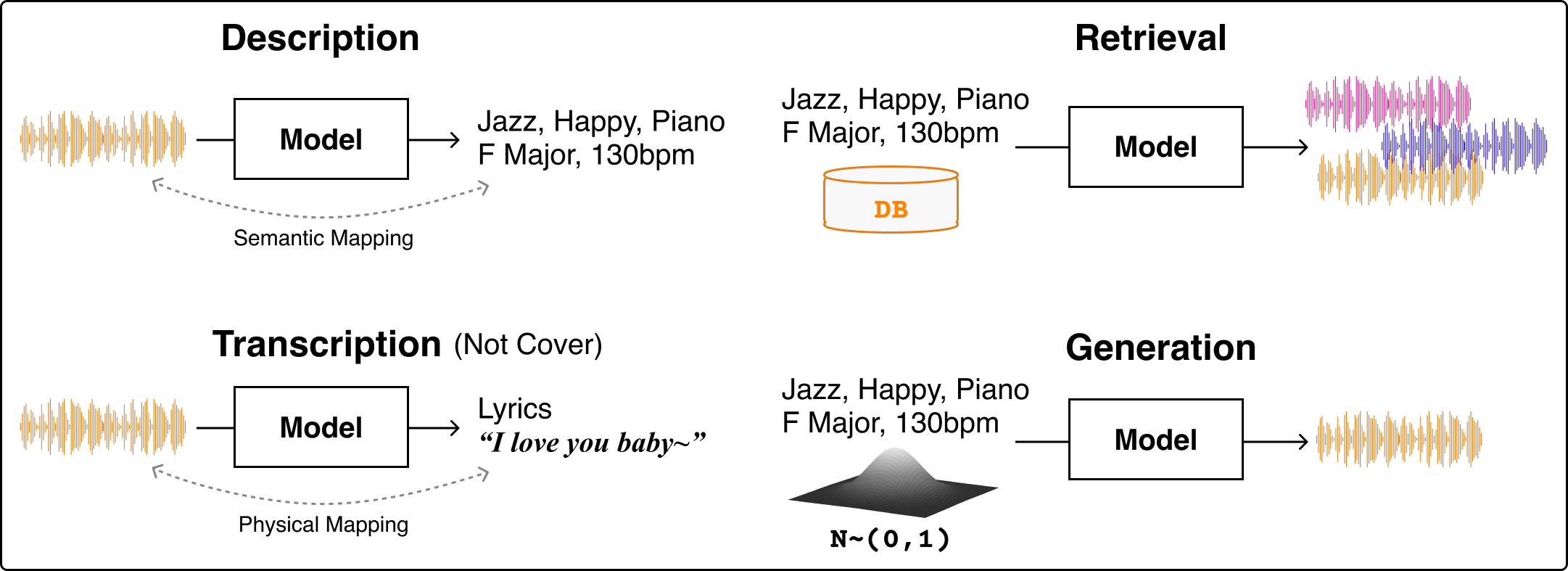
Fig. 1 音乐与语言连接框架概览。在本教程中,我们重点讲解描述、检索和生成三个方面。但不包括转录部分的讨论。#
我们坚信MIR社区将从本教程中获得实质性的收益。我们的讨论不仅将强调为什么将音乐与语言模型相结合的多模态方法标志着与传统任务特定模型的重大突破,还将详细梳理该领域的最新进展、未解决的挑战以及潜在的未来发展方向。同时,我们旨在建立坚实的基础,通过提供相关数据集、评估方法和编码最佳实践的全面资源,鼓励新兴研究者参与音乐-语言研究领域,从而营造一个包容且创新的研究环境。
快速开始#
本电子书由一系列Jupyter笔记本组成,可以在本页面上静态浏览。如需自行运行笔记本,您需要克隆Git仓库:
git clone https://github.com/mulab-mir/music-language-tutorial/ && cd music-language-tutorial
conda create --name p310 python==3.10 && conda activate python
接下来,安装依赖项:
pip install -r requirements.txt
最后,启动Jupyter笔记本服务器:
jupyter notebook
关于作者#

SeungHeon Doh 是韩国科学技术院(KAIST)音乐与音频计算实验室的博士研究生,师从Juhan Nam教授。他的研究方向聚焦于对话式音乐描述、检索和生成。SeungHeon在ISMIR、ICASSP和IEEE TASLP等会议和期刊上发表了与音乐和语言模型相关的论文。他致力于使机器能够在对话中理解多种模态,从而通过对话促进音乐的理解和发现。SeungHeon曾在Chartmetric、NaverCorp和字节跳动实习,将其专业知识应用于实际场景。

Ilaria Manco 是伦敦玛丽女王大学人工智能与音乐博士培训中心的博士生,导师为Emmanouil Benetos、George Fazekas和Elio Quinton(UMG)。她的研究方向是面向音乐信息检索的多模态深度学习,重点关注音频-语言模型在音乐理解中的应用。她的研究成果已在ISMIR和ICASSP上发表,包括首个音乐字幕生成模型以及连接音乐与语言的表示学习方法。此前,她曾在Google DeepMind、Adobe和索尼担任研究实习生,并获得帝国理工学院物理学硕士学位。

Zachary Novack 是加州大学圣地亚哥分校的博士生,导师为Julian McAuley和Taylor Berg-Kirkpatrick。他的研究主要针对高效且可控的音乐和音频生成。具体而言,Zachary致力于构建允许灵活的音乐相关控制的生成式音乐模型,同时加速这些模型以便在实际生产流程中使用。Zachary曾在Stability AI和Adobe Research实习,参与了DITTO-(1/2)和Presto!等项目。在学术之外,Zachary热衷于音乐教育,在南加州地区教授打击乐。

Jong Wook Kim 是OpenAI的技术人员,参与过Jukebox、CLIP、Whisper和GPT-4等多模态深度学习模型的研发。他在ICML、CVPR、ICASSP、IEEE SPM和ISMIR上发表过论文,并在NeurIPS 2021会议上共同主持了自监督学习教程。他在纽约大学获得音乐技术博士学位,博士论文聚焦于自动音乐转录,并拥有密歇根大学安娜堡分校计算机科学与工程硕士学位。他在攻读博士期间曾在Pandora和Spotify实习,此前在NCSOFT和Kakao担任软件工程师。

Ke Chen 是加州大学圣地亚哥分校计算机科学与工程系的博士研究生。他的研究兴趣横跨音乐和音频表示学习,特别关注其在音乐生成式AI、音源分离、多模态学习和音乐信息检索等下游应用。他曾在苹果、三菱、腾讯、字节跳动和Adobe实习,进一步探索研究方向。在攻读博士学位期间,Ke Chen在人工智能、信号处理和音乐领域的顶级会议上发表了20余篇论文,如AAAI、ICASSP和ISMIR。在学术之外,他热衷于各种音乐活动,包括钢琴演奏、声乐和音乐创作。