对话式检索#
基于上一章讨论的单轮检索系统的局限性,开发能够在多次交互中保持上下文的对话式音乐检索功能正受到越来越多的关注。本章探讨对话式方法如何解决当前系统的根本局限性,同时创造更自然、更具交互性的音乐发现体验。
单轮系统的局限性#
如前所述,当前的音乐检索系统由于其单轮特性而面临几个关键局限:
查询之间丢失宝贵的搜索上下文
无法从用户反馈和先前交互中学习
对自然查询细化的支持有限
错失引导式音乐探索的机会
对话式音乐检索(Conversational music retrieval)代表了解决这些局限性的一个有前景的方向,它通过基于聊天的界面实现多轮交互。与传统系统中每个查询被独立处理不同,对话式方法维护对话历史,以随时间建立对用户需求更深入的理解。
对话式检索的主要优势#
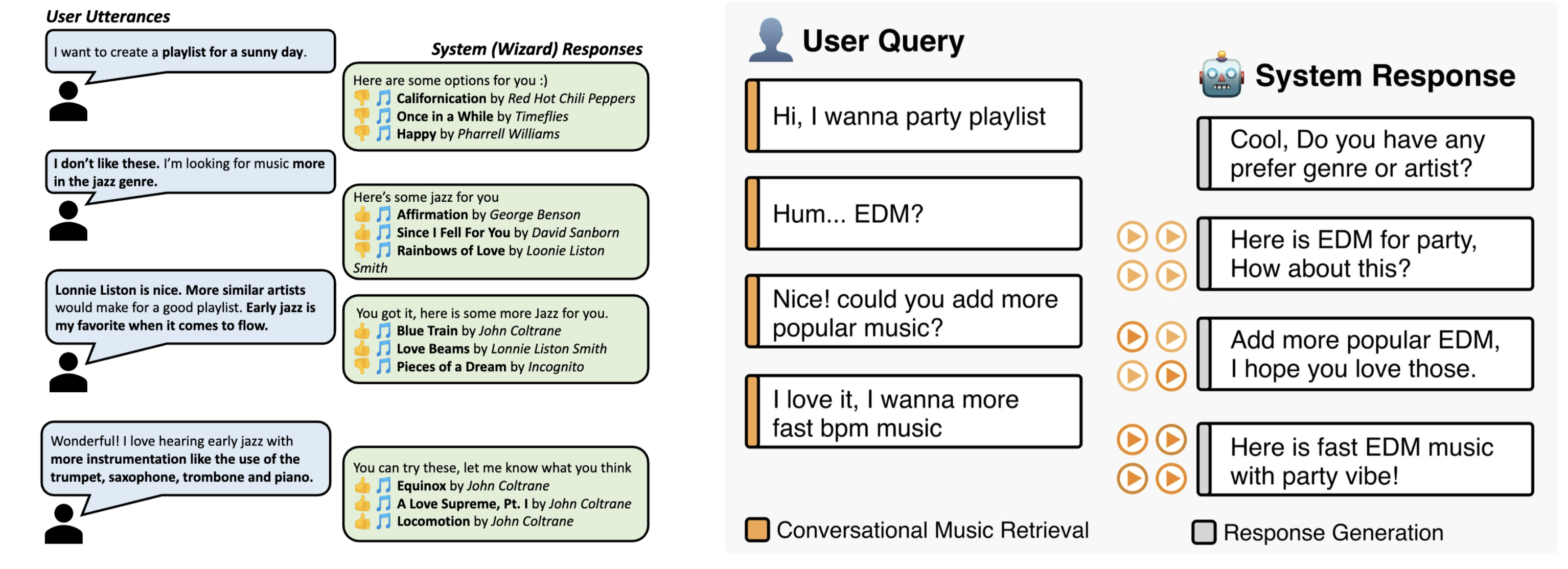
对话式方法提供了几个重要优势,近期在开发对话式音乐检索数据集方面的研究成果已经证明了这一点。例如,Chaganty et al.[CLZ+23] 引入了 Conversational Playlist Curation Dataset (CPCD),包含 917 段多轮对话,平均每段有 5.7 个对话轮次。他们的工作突出了对话式检索的关键优势。此外,[LZG+23] 和 [DCK+24] 通过合成音乐发现对话的生成来解决多轮检索数据有限的挑战,从而提高了性能。
除了数据集之外,这些工作还讨论了对话式音乐检索模型的优势和未来方向。他们强调,对话式方法通过维护对话上下文并随时间从用户反馈中学习,能够实现更自然、更直观的音乐发现。研究表明,未来的模型应专注于通过对话历史更好地理解用户意图、生成更具吸引力的响应,以及开发更复杂的检索机制来处理通过对话表达的细微音乐查询和偏好。
关键技术挑战#
然而,构建有效的对话式音乐检索系统面临几个重大技术挑战:
联合检索与响应生成:系统不仅需要检索相关音乐,还需要生成适当的对话响应。这需要仔细集成检索和语言生成能力。
上下文整合:先前的对话历史需要被有效地纳入检索和生成过程中,以维持连贯的对话。
超越简单相似度:传统的嵌入相似度度量可能不足以捕捉对话式搜索中所需的细微关系。
自然的查询细化:系统需要复杂的理解能力来处理比较性和细化性查询(例如,”像这个但更欢快”)。
未来方向#
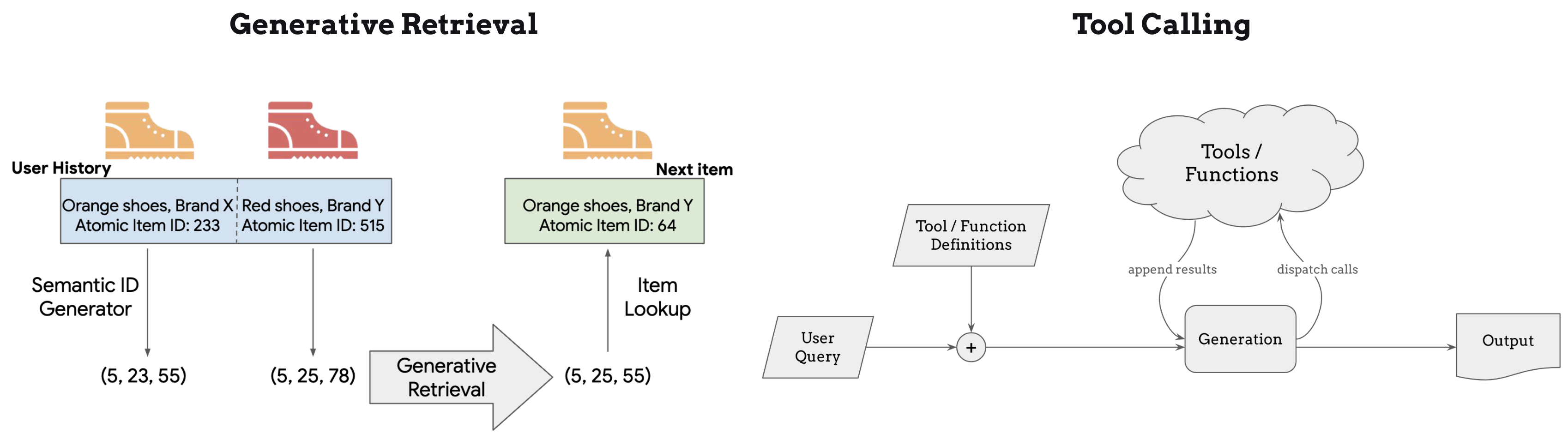
若干有前景的研究方向正在涌现以应对这些挑战:
生成式检索(Generative Retrieval):从纯粹基于相似度的检索转向能够根据对话上下文生成或组合查询的方法
工具调用系统(Tool-Calling Systems):利用能够将检索系统作为工具调用的大语言模型,在通过专用检索组件保持稳健搜索能力的同时实现自然语言交互
虽然仍存在重大挑战,但对话式音乐检索代表了我们与音乐交互和发现音乐方式的重要演进。该领域的成功可以通过持续的对话来使音乐搜索体验变得更自然、更具上下文感知、更有效地服务于用户多样化的音乐需求,从而显著改善音乐搜索体验。
参考文献#
Arun Tejasvi Chaganty, Megan Leszczynski, Shu Zhang, Ravi Ganti, Krisztian Balog, and Filip Radlinski. Beyond single items: exploring user preferences in item sets with the conversational playlist curation dataset. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2023.
SeungHeon Doh, Keunwoo Choi, Daeyong Kwon, Taesu Kim, and Juhan Nam. Music discovery dialogue generation using human intent analysis and large language models. arXiv preprint arXiv:2411.07439, 2024.
Megan Leszczynski, Shu Zhang, Ravi Ganti, Krisztian Balog, Filip Radlinski, Fernando Pereira, and Arun Tejasvi Chaganty. Talk the walk: synthetic data generation for conversational music recommendation. arXiv preprint arXiv:2301.11489, 2023.