教程概览#
本教程将介绍随着语言模型的发展,音乐理解、检索和生成技术所发生的变化。
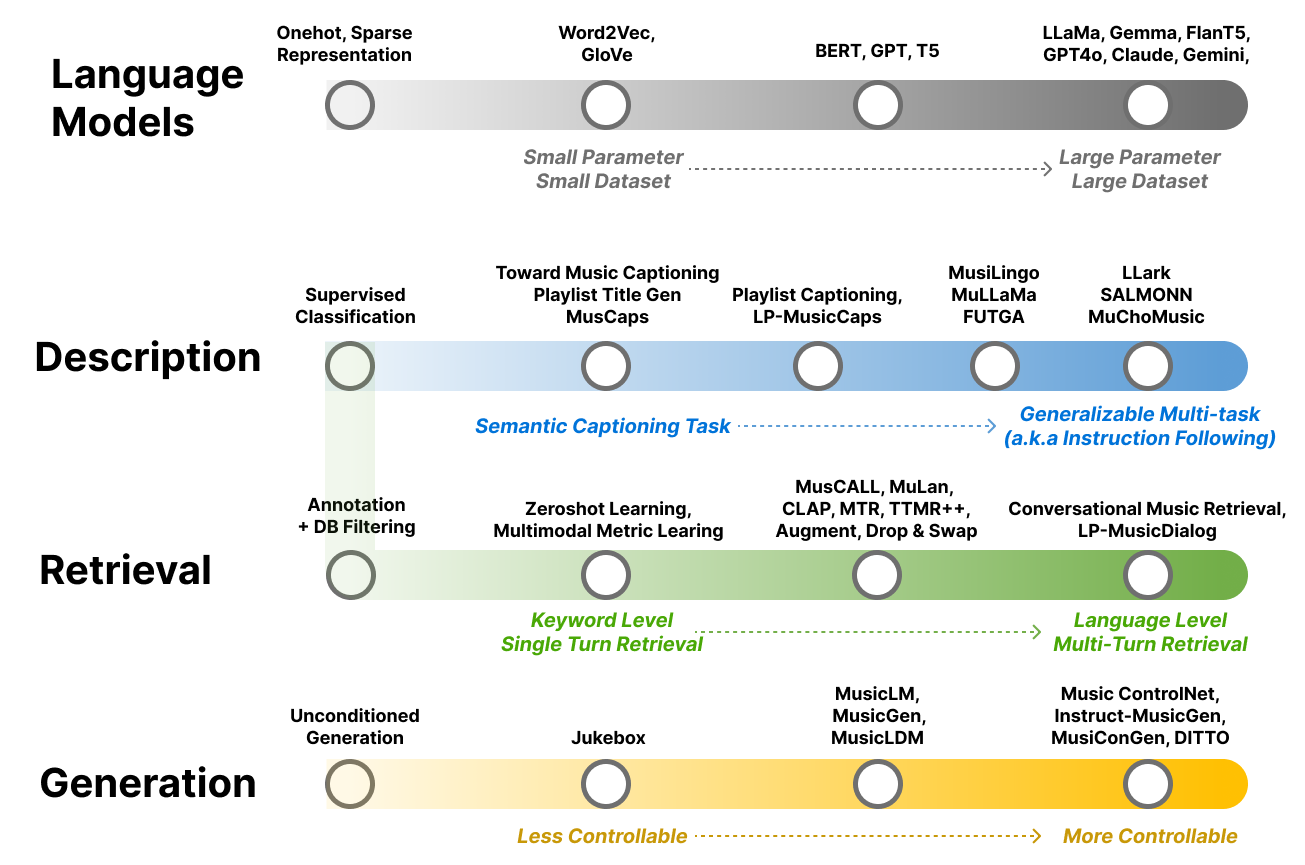
Fig. 3 音乐与语言模型发展的示意图。#
语言模型#
第2章介绍了语言模型(Language Models, LMs),它们对于使机器理解自然语言及其广泛应用至关重要。本章追溯了从简单的 one-hot 编码和词嵌入(word embedding)到更高级语言模型的发展历程,包括掩码语言模型(masked language model)[DCLT18]、自回归语言模型(auto-regressive language model)[RWC+19] 以及编码器-解码器语言模型(encoder-decoder language model)[RSR+20],进而发展到前沿的指令跟随(instruction-following)[WBZ+21] [OWJ+22] [CHL+24] 和大语言模型(large language models)[AAA+23]。此外,我们还回顾了语言模型的组成部分和条件方法,并探讨了将语言模型作为框架使用时面临的挑战和潜在的解决方案。
音乐描述#
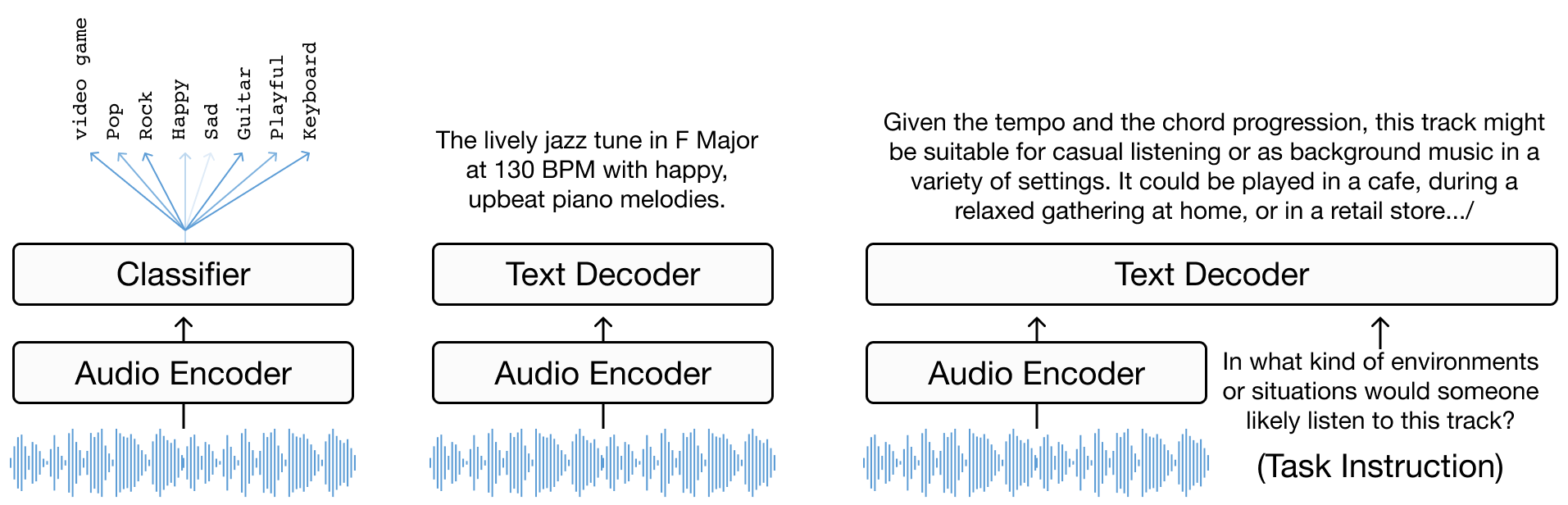
第3章深入探讨了音乐标注作为增强音乐理解的工具。本章首先定义了任务和问题形式化,从基础的分类 [TBTL08] [NCL+18] 过渡到更复杂的语言解码任务。接着,本章进一步探索了编码器-解码器模型 [MBQF21] [DCLN23] 以及多模态大语言模型(LLMs)在音乐理解中的作用 [GDSB23]。本章探讨了从”针对特定任务的分类模型”到”使用多样化自然语言监督训练的更通用的多任务模型”的演变过程。
音乐检索#
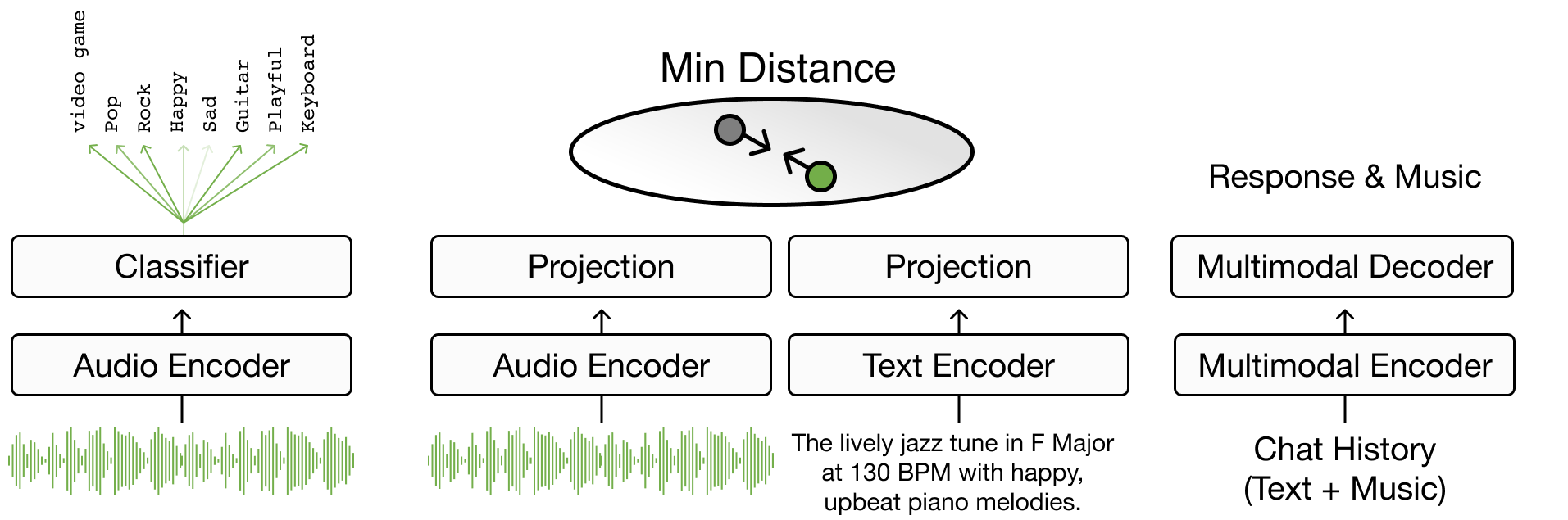
第4章聚焦于文本到音乐的检索(text-to-music retrieval),这是音乐搜索的关键组成部分,详细介绍了该任务的定义和各种搜索方法。内容涵盖从基本的布尔搜索和向量搜索到通过联合嵌入方法(joint embedding)[CLPN19] 将词语与音乐连接起来的高级技术,解决了词汇表外(out-of-vocabulary)等问题。本章进一步发展到句子到音乐的检索 [HJL+22] [MBQF22] [DWCN23],探索如何整合复杂的音乐语义,以及基于多轮对话的会话式音乐检索 [CLZ+23]。本章介绍了评估指标,并包含开发基本联合嵌入模型用于音乐搜索的实践编程练习。本章的核心是模型如何以各种方式响应”用户的音乐查询”。
音乐生成#
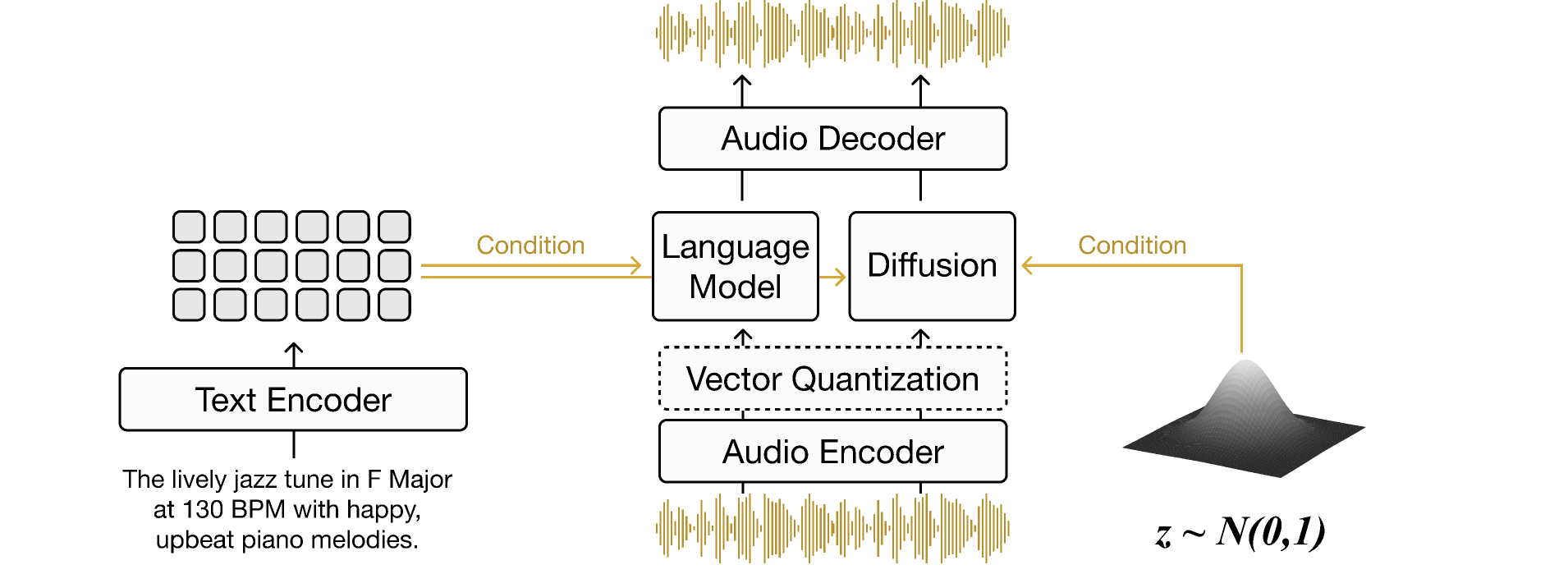
第5章深入探讨了通过文本到音乐生成(text-to-music generation)技术创作新音乐的方法,重点介绍了在文本提示影响下产生新声音的过程 [DJP+20]。本章介绍了无条件音乐生成的概念,并详细说明了在训练阶段融入文本线索的方法。讨论内容包括相关数据集的概述以及基于听觉质量和文本相关性的音乐评估。本章比较了不同的音乐生成方法,包括扩散模型(diffusion models)[CWL+24] 和离散编解码器语言模型(discrete codec language models)[ADB+23] [CKG+24]。此外,本章还探讨了纯文本驱动生成面临的挑战,并研究了超越文本的替代条件生成方法,例如将文本描述转换为音乐属性 [WDWB23] [NMBKB24]。
参考文献#
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, and others. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
Andrea Agostinelli, Timo I Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, and others. Musiclm: generating music from text. arXiv preprint arXiv:2301.11325, 2023.
Arun Tejasvi Chaganty, Megan Leszczynski, Shu Zhang, Ravi Ganti, Krisztian Balog, and Filip Radlinski. Beyond single items: exploring user preferences in item sets with the conversational playlist curation dataset. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2023.
Ke Chen, Yusong Wu, Haohe Liu, Marianna Nezhurina, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. MusicLDM: enhancing novelty in text-to-music generation using beat-synchronous mixup strategies. In IEEE International Conference on Audio, Speech and Signal Processing (ICASSP). 2024.
Jeong Choi, Jongpil Lee, Jiyoung Park, and Juhan Nam. Zero-shot learning for audio-based music classification and tagging. In ISMIR. 2019.
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, and others. Scaling instruction-finetuned language models. Journal of Machine Learning Research, 25(70):1–53, 2024.
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Défossez. Simple and controllable music generation. Advances in Neural Information Processing Systems, 2024.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, and Ilya Sutskever. Jukebox: a generative model for music. arXiv preprint arXiv:2005.00341, 2020.
SeungHeon Doh, Keunwoo Choi, Jongpil Lee, and Juhan Nam. Lp-musiccaps: llm-based pseudo music captioning. In International Society for Music Information Retrieval (ISMIR). 2023.
SeungHeon Doh, Minz Won, Keunwoo Choi, and Juhan Nam. Toward universal text-to-music retrieval. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1–5. IEEE, 2023.
Josh Gardner, Simon Durand, Daniel Stoller, and Rachel M Bittner. Llark: a multimodal foundation model for music. arXiv preprint arXiv:2310.07160, 2023.
Qingqing Huang, Aren Jansen, Joonseok Lee, Ravi Ganti, Judith Yue Li, and Daniel PW Ellis. Mulan: a joint embedding of music audio and natural language. arXiv preprint arXiv:2208.12415, 2022.
Ilaria Manco, Emmanouil Benetos, Elio Quinton, and György Fazekas. Muscaps: generating captions for music audio. In 2021 International Joint Conference on Neural Networks (IJCNN), 1–8. IEEE, 2021.
Ilaria Manco, Emmanouil Benetos, Elio Quinton, and György Fazekas. Contrastive audio-language learning for music. arXiv preprint arXiv:2208.12208, 2022.
Juhan Nam, Keunwoo Choi, Jongpil Lee, Szu-Yu Chou, and Yi-Hsuan Yang. Deep learning for audio-based music classification and tagging: teaching computers to distinguish rock from bach. IEEE signal processing magazine, 2018.
Zachary Novack, Julian McAuley, Taylor Berg-Kirkpatrick, and Nicholas J. Bryan. DITTO: Diffusion inference-time T-optimization for music generation. In International Conference on Machine Learning (ICML). 2024.
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and others. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 2022.
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, and others. Language models are unsupervised multitask learners. OpenAI blog, 2019.
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020.
Douglas Turnbull, Luke Barrington, David Torres, and Gert Lanckriet. Semantic annotation and retrieval of music and sound effects. IEEE Transactions on Audio, Speech, and Language Processing, 16(2):467–476, 2008.
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652, 2021.
Shih-Lun Wu, Chris Donahue, Shinji Watanabe, and Nicholas J Bryan. Music controlnet: multiple time-varying controls for music generation. arXiv preprint arXiv:2311.07069, 2023.