挑战#
虽然音频-文本联合嵌入模型已经推动了检索系统的重大进步,但仍然存在若干开放性挑战。在本章中,我们回顾三个主要问题:
查询-描述分布不匹配:用户自然表述查询的方式与用于训练检索模型的描述之间通常存在显著差距。训练数据集通常包含正式的描述或技术性标注,而真实用户查询往往更加口语化且表达方式更加多样。
单轮检索的局限性:当前的检索系统大多以单轮方式运行,每个查询被独立处理。这无法捕捉音乐发现过程中天然的来回交互特性,用户通常会根据先前的结果来细化搜索,并可能希望探索相关但不同的音乐方向。
查询-描述分布不匹配#

当前的描述数据集不幸地几乎完全聚焦于音乐属性,缺乏对音乐更广泛文化方面的覆盖。例如,[MWD+23] 提出的 Song Describer dataset 仅限于流派、风格、情绪、质感、乐器和结构等技术性音乐属性。虽然这些属性很重要,但它们忽略了用户关心的许多其他维度——如文化历史意义、艺术家背景,或与其他艺术家和歌曲的相似性。该数据集也倾向于使用正式的、分析性的语言,而非人们通常描述和搜索音乐时更自然的、口语化的方式。这种狭隘的聚焦在覆盖用户完整的音乐需求和搜索行为方面留下了显著的空白。如果训练数据无法捕捉人们与音乐关联和发现音乐的这些更广泛方面,检索系统可能难以有效服务于真实世界的用例,即用户希望基于声学特征以外的更多方面来寻找音乐。
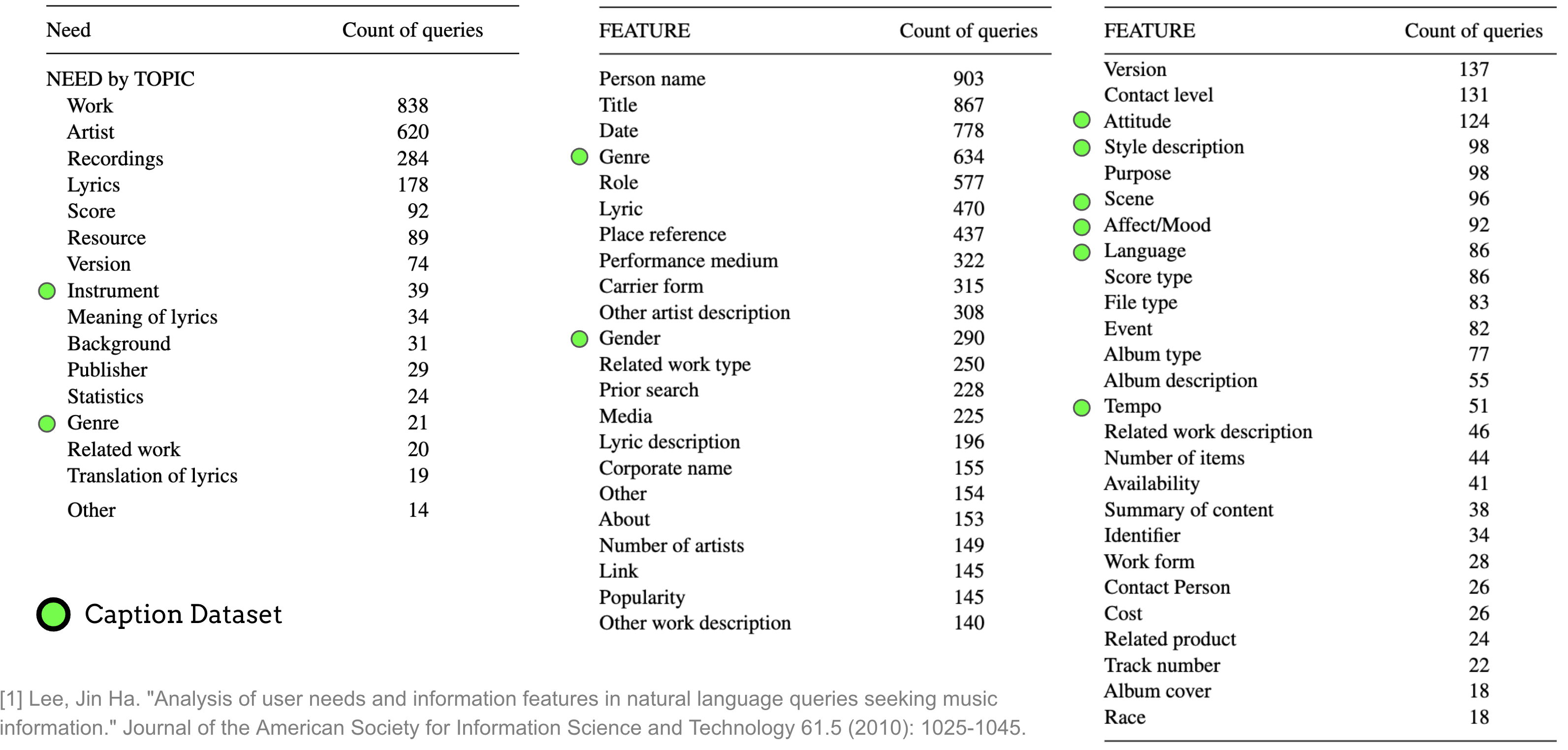
我们需要回顾先前关于用户查询理解的研究。在 [Lee10] 中,按主题对用户查询需求的分析揭示了比当前系统通常处理的范围更广泛的音乐需求。例如,关于歌词、乐谱、出版商和日期的信息在当前的音乐描述数据集中明显缺失。最近,[DCK+24] 对 917 段与音乐相关的对话进行了定性分析,发现用户不仅对基于音乐内容信息的搜索感兴趣,还对基于用户信息、元数据和其他多样化方面的查询感兴趣。
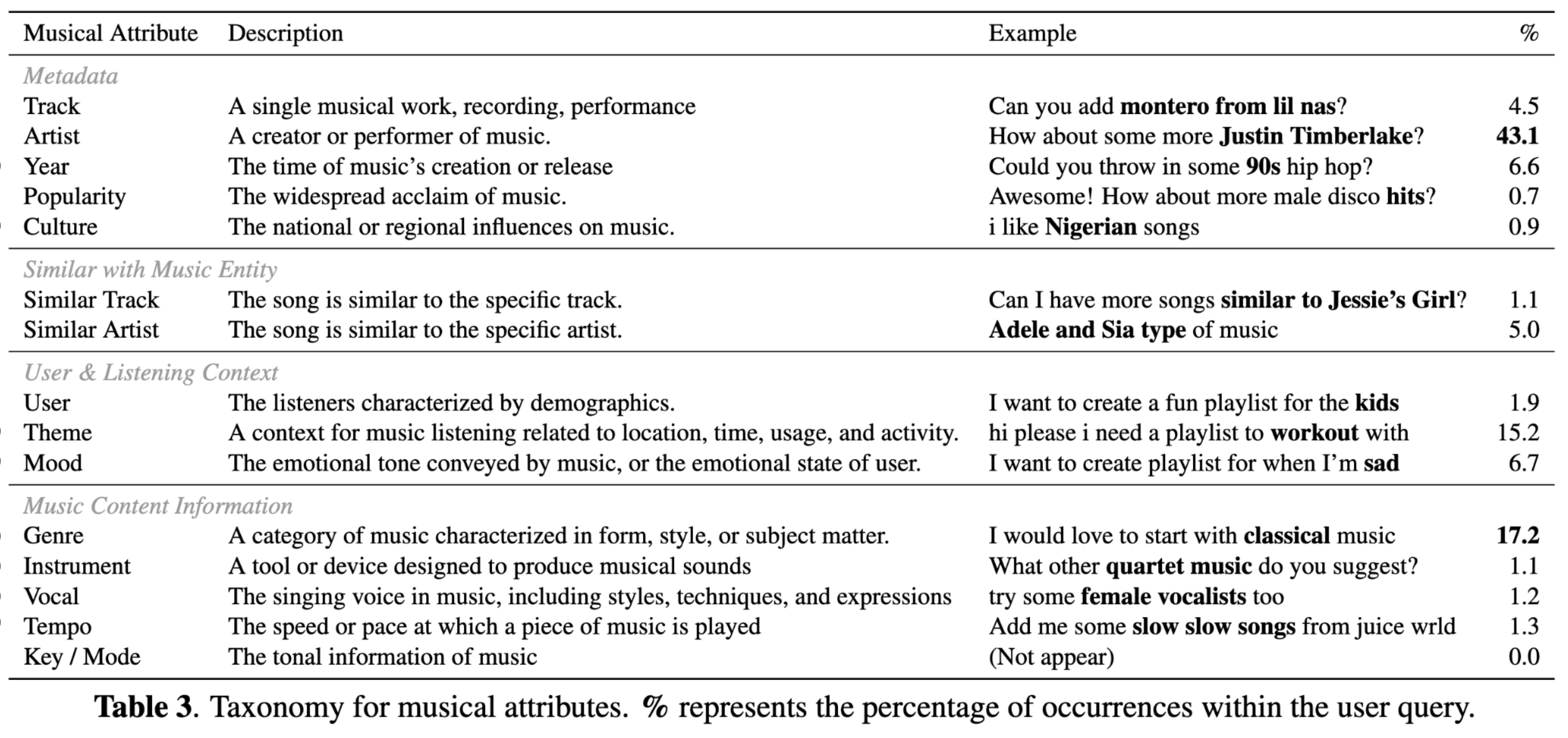
这些研究凸显了当前检索系统的训练方式与实际用户需求之间的显著差距。虽然现代描述数据集主要聚焦于音乐内容描述,但真实用户通过更加丰富多样的查询来寻找音乐,这些查询涵盖了文化、上下文和基于元数据的信息。这种不匹配限制了当前检索系统在服务自然用户查询方面的有效性。
单轮检索的局限性#
当前的音乐检索系统主要设计用于单轮交互,每个查询被视为一个独立事件。然而,这种方法无法捕捉音乐发现过程中固有的迭代性和对话性。当用户搜索音乐时,他们通常需要多次尝试才能找到想要的内容,根据先前的结果和系统响应来细化查询。
考虑一个典型场景:用户发出初始查询但对结果不完全满意。在自然的发现过程中,他们会在第一次交互的基础上进一步探索——也许会指定额外的标准、请求初始结果的变体,或将搜索引向稍有不同的方向。然而,当前的单轮系统将每个新查询视为完全全新的开始,丢弃了先前交互中的宝贵上下文。
这一局限性产生了几个关键问题:
搜索上下文的丢失:每个新查询都从头开始,忽略了用户搜索历史和先前交互中包含的宝贵信息。这迫使用户反复提供本可以从其搜索轨迹中推断出的上下文。
无法从反馈中学习:系统无法有效地从用户对先前结果的隐式或显式反馈中学习以改善后续推荐。当用户修改查询时,系统不理解先前结果的哪些方面不令人满意。
有限的细化能力:用户无法通过迭代交互自然地细化搜索。他们无法说”像那样,但更欢快”或”类似但用不同的乐器”,而必须制定全新的查询。
错失的探索机会:系统无法根据用户不断变化的偏好和对先前结果的反应,引导用户自然地探索音乐空间,建议相关但不同的方向。
为了解决这些局限性,未来的检索系统需要纳入多轮交互能力,能够:
在多次交互中维护对话历史和上下文
理解初始结果何时未完全满足用户意图
利用先前的交互来指导和改善后续推荐
支持自然的查询细化和探索模式
这种向对话式音乐检索的演进将更好地与人们自然发现和探索音乐的方式保持一致,从而带来更令人满意和更有效的搜索体验。
参考文献#
SeungHeon Doh, Keunwoo Choi, Daeyong Kwon, Taesu Kim, and Juhan Nam. Music discovery dialogue generation using human intent analysis and large language models. arXiv preprint arXiv:2411.07439, 2024.
Jin Ha Lee. Analysis of user needs and information features in natural language queries seeking music information. Journal of the American Society for Information Science and Technology, 61(5):1025–1045, 2010.
Ilaria Manco, Benno Weck, Seungheon Doh, Minz Won, Yixiao Zhang, Dmitry Bodganov, Yusong Wu, Ke Chen, Philip Tovstogan, Emmanouil Benetos, and others. The song describer dataset: a corpus of audio captions for music-and-language evaluation. arXiv preprint arXiv:2311.10057, 2023.