任务#
音乐描述涵盖多种不同的任务。 下面我们逐一详细介绍,从输出形式最简单的任务(类别标签)到产生更复杂的基于自然语言输出的任务。通过这一过程,我们也回顾了基于深度学习的 AMU 系统的发展历程。
音乐分类#
传统上,MIR 领域的音乐描述是通过有监督的基于分类的系统来实现的,这些系统学习根据音频输入预测一个(或多个)标签,每个标签对应一个特定的、预先分配的描述符。 例如,我们可以训练分类器来根据流派 [TC02]、乐器 [PHBD03]、情绪 [KSM+10] 等类别描述音乐。 有时也会使用多标签分类(auto-tagging,即自动标注)来分配涵盖多个类别的标签,通常包括流派、情绪、乐器和年代 [CFSC17] [LN17] [WCS21]。
分类器 \(f\) 将音频映射到从一个预定义的、通常规模较小的 \(K\) 个标签集合中选出的类别标签,\(f: \mathcal{X} \rightarrow \{0, \dots, 1-K\}\)。因此,这种描述方式在表达能力上是有限的,因为它无法适应新概念,也无法建模标签之间的关系。

Note
如果您想了解更多关于音乐分类的内容,2021 年有一个涵盖此主题的 ISMIR 教程。
Music Captioning(音乐字幕生成)#
正因如此,近年来音乐描述的研究已转向融入自然语言,开发将音频输入映射到完整句子的模型,\(g: \mathcal{X} \rightarrow \mathcal{V}^*\)。在此情况下,\(\mathcal{V}\) 是词汇表,\(\mathcal{V}^*\) 表示可以由 \(\mathcal{V}\) 中元素组成的所有可能序列。借助自然语言的优势,这些系统能够产生更加细腻、富有表现力且接近人类的描述。
基于语言的音乐描述任务的主要范例是 music captioning(音乐字幕生成),其目标是生成描述音频输入的自然语言输出:
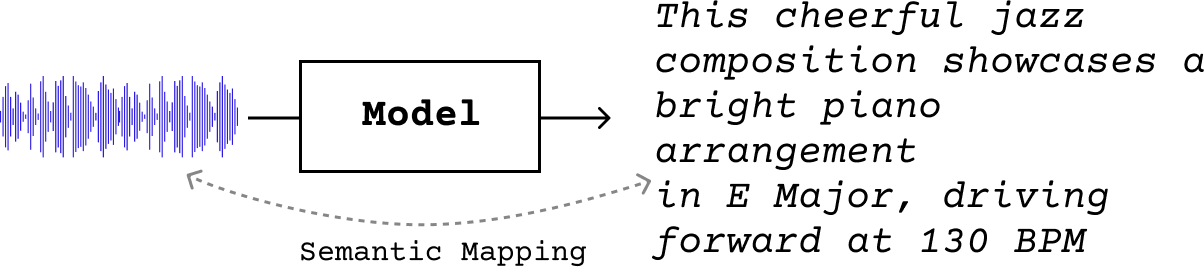
我们可以将其视为一种条件语言模型,其中我们不仅根据先前的文本 token \(y_{i<t}\),还根据音频 \(a\) 来预测序列 \(Y\)(长度为 \(L\))中的下一个 token \(y_t\):
Music captioning 的类型#
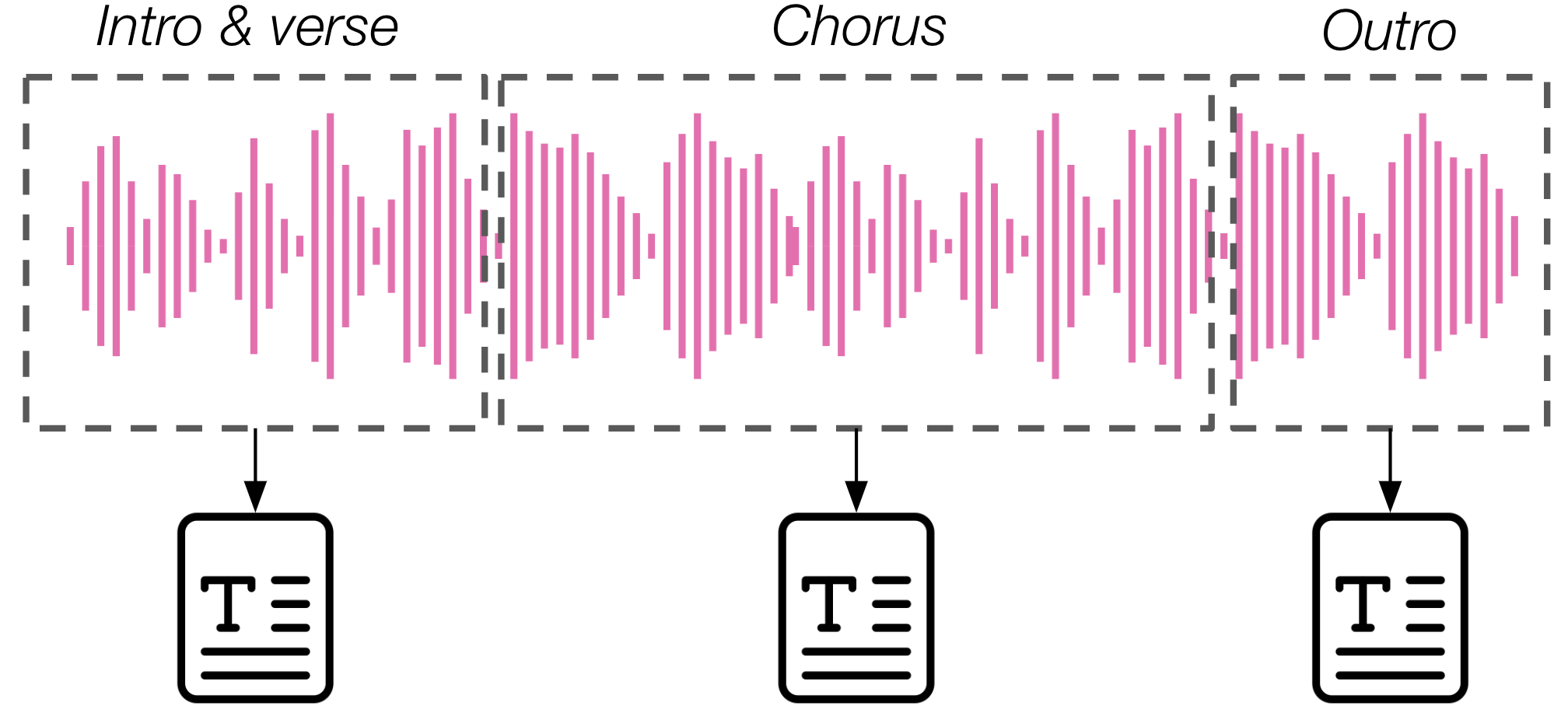
Music captioning 可以在子轨道、轨道或多轨道级别执行,取决于音频输入是较长轨道中的一个片段(通常为固定长度)、完整的变长轨道,还是多个轨道的序列(即播放列表)。在后一种情况下,我们通常将这种描述任务称为 playlist captioning(播放列表字幕生成)[GHE22]。而当我们使用 music captioning 这一术语时,通常指的是对片段或完整轨道的字幕生成 [MBQF21] [MBQF21] [WNN+24]。在 music captioning 任务的一个变体中,除音频外还可以将歌词作为额外输入数据来生成描述,但这仅在一项先前研究中有所探索 [HHL+23]。
Music captioning 通常侧重于描述内容的全局特征,尤其是那些在相对较长时间尺度(约10-30秒)上呈现的特征,例如风格和流派。在许多情况下,这类字幕不包含对时间定位事件、时间顺序、结构或其他时间感知描述的引用,只能传达音乐作品的高层次、粗粒度摘要。然而,音频信号中的时间演变是音乐的一个关键方面。因此,该任务的更新变体着重于生成能够捕捉结构特征的更细粒度的字幕 [WNN+24]。
Music Question Answering(音乐问答)#
伴随着更灵活和细粒度的 music captioning,音乐描述的最新发展已经开始超越静态字幕生成,转向更具交互性的、基于对话的描述。一个主要的例子是 music question answering(MQA,音乐问答),其目标是获得针对给定音乐作品回答问题的语言输出:

MQA 任务相对较新,我们在文献中发现的最早例子来自 Gao et al. (2023) [GLTQ23]。在他们的工作中,作者提出了一个由 (music, question, answer) 元组组成的数据集,并提出了一个基线模型,该模型根据音乐-问题输入以及美学知识库中的条目来预测答案。
然而,MQA 任务是在多模态自回归模型(如 LLark [GDSB23]、MusiLingo [DML+24] 和 MuLLaMa)发展之后才真正确立起来的,我们将在模型章节中更详细地讨论这些模型。
对话式音乐描述#
最后,通过对话式音乐描述或音乐对话生成可以实现更加通用的音乐描述形式,其目标是以多轮对话的方式,针对语言输入和伴随的音乐音频生成合适的语言输出:
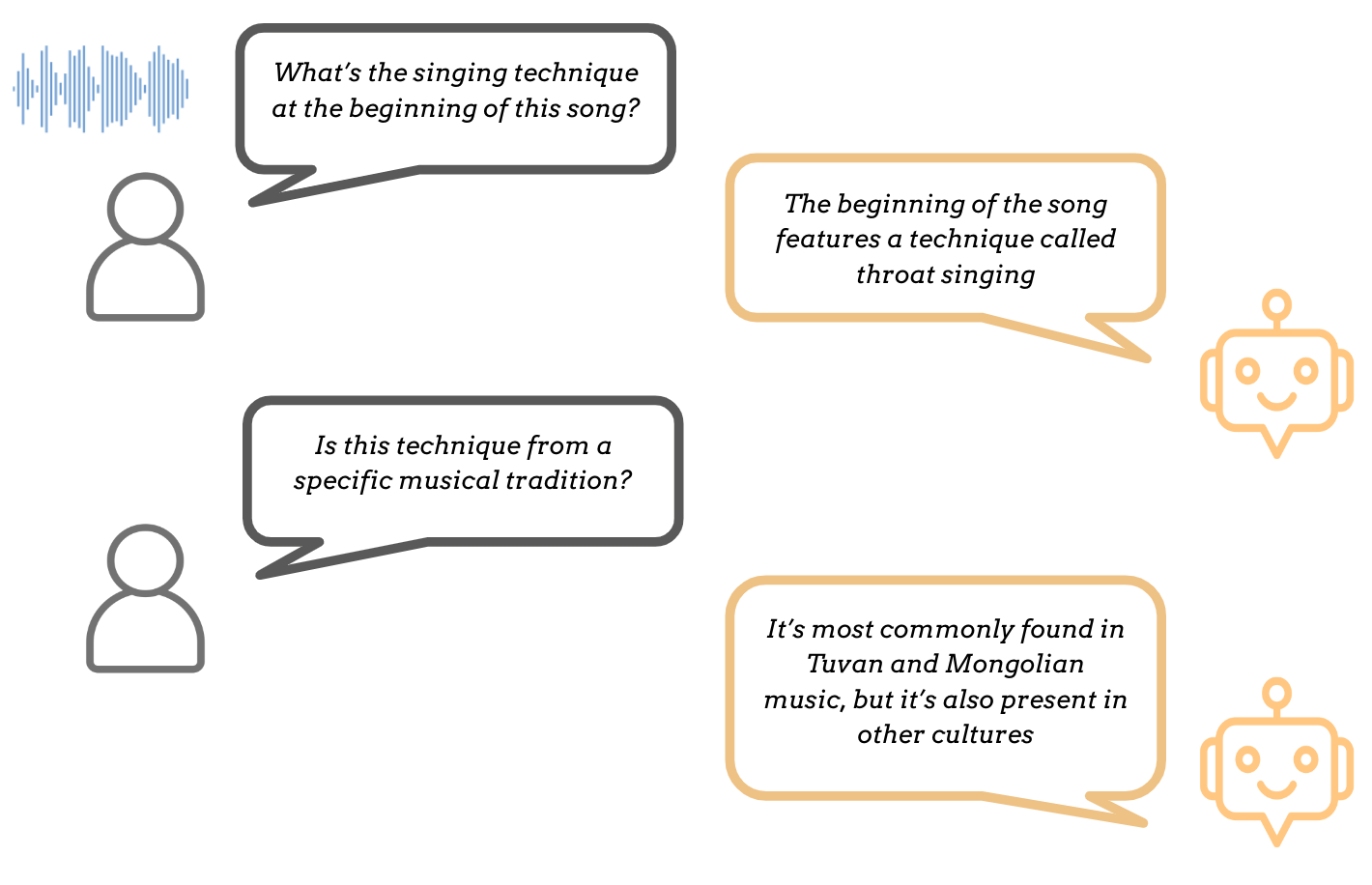
基于对话的描述与一次性字幕生成之间的一个关键区别在于,我们现在处理的不再是 audio --> text 的映射,而是 (audio, text) --> text 的映射。这种区别体现在这些任务通常采用不同的模型设计中(参见模型)。与简单的 MQA 不同,在音乐对话生成中,回复需要基于整个对话历史,而不仅仅考虑当前输入。
在实际应用方面,基于对话的描述优势显而易见:它不再局限于一次性的字幕或回答,而是允许用户提供文本输入来进一步指示模型应该包含哪些信息,或者文本输出本身应如何组织。简而言之,这些任务提供了一种更加灵活的方法,更好地反映了真实使用场景。一个缺点是它们更难评估(参见评估)!
参考文献#
Keunwoo Choi, György Fazekas, Mark Sandler, and Kyunghyun Cho. Convolutional recurrent neural networks for music classification. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), volume, 2392–2396. 2017. doi:10.1109/ICASSP.2017.7952585.
Zihao Deng, Yinghao Ma, Yudong Liu, Rongchen Guo, Ge Zhang, Wenhu Chen, Wenhao Huang, and Emmanouil Benetos. MusiLingo: Bridging Music and Text with Pre-trained Language Models for Music Captioning and Query Response. In Kevin Duh, Helena Gomez, and Steven Bethard, editors, Findings of the Association for Computational Linguistics: NAACL 2024, 3643–3655. Mexico City, Mexico, June 2024. Association for Computational Linguistics. URL: https://aclanthology.org/2024.findings-naacl.231 (visited on 2024-07-04).
Giovanni Gabbolini, Romain Hennequin, and Elena Epure. Data-efficient playlist captioning with musical and linguistic knowledge. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors, Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 11401–11415. Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. URL: https://aclanthology.org/2022.emnlp-main.784, doi:10.18653/v1/2022.emnlp-main.784.
Wenhao Gao, Xiaobing Li, Yun Tie, and Lin Qi. Music Question Answering Based on Aesthetic Experience. In 2023 International Joint Conference on Neural Networks (IJCNN), 01–06. June 2023. ISSN: 2161-4407. URL: https://ieeexplore.ieee.org/abstract/document/10191775 (visited on 2024-03-01), doi:10.1109/IJCNN54540.2023.10191775.
Josh Gardner, Simon Durand, Daniel Stoller, and Rachel M Bittner. Llark: a multimodal foundation model for music. arXiv preprint arXiv:2310.07160, 2023.
Zihao He, Weituo Hao, Wei-Tsung Lu, Changyou Chen, Kristina Lerman, and Xuchen Song. Alcap: alignment-augmented music captioner. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 16501–16512. 2023.
Youngmoo E Kim, Erik M Schmidt, Raymond Migneco, Brandon G Morton, Patrick Richardson, Jeffrey Scott, Jacquelin A Speck, and Douglas Turnbull. Music emotion recognition: a state of the art review. In Proc. ismir, volume 86, 937–952. 2010.
Jongpil Lee and Juhan Nam. Multi-level and multi-scale feature aggregation using pretrained convolutional neural networks for music auto-tagging. IEEE Signal Processing Letters, 24(8):1208–1212, 2017. doi:10.1109/LSP.2017.2713830.
Ilaria Manco, Emmanouil Benetos, Elio Quinton, and György Fazekas. Muscaps: generating captions for music audio. In 2021 International Joint Conference on Neural Networks (IJCNN), 1–8. IEEE, 2021.
Geoffroy Peeters Perfecto Herrera-Boyer and Shlomo Dubnov. Automatic classification of musical instrument sounds. Journal of New Music Research, 32(1):3–21, 2003. doi:10.1076/jnmr.32.1.3.16798.
G. Tzanetakis and P. Cook. Musical genre classification of audio signals. IEEE Transactions on Speech and Audio Processing, 10(5):293–302, 2002. doi:10.1109/TSA.2002.800560.
Minz Won, Keunwoo Choi, and Xavier Serra. Semi-supervised music tagging transformer. In Proc. of International Society for Music Information Retrieval. 2021.