简介#
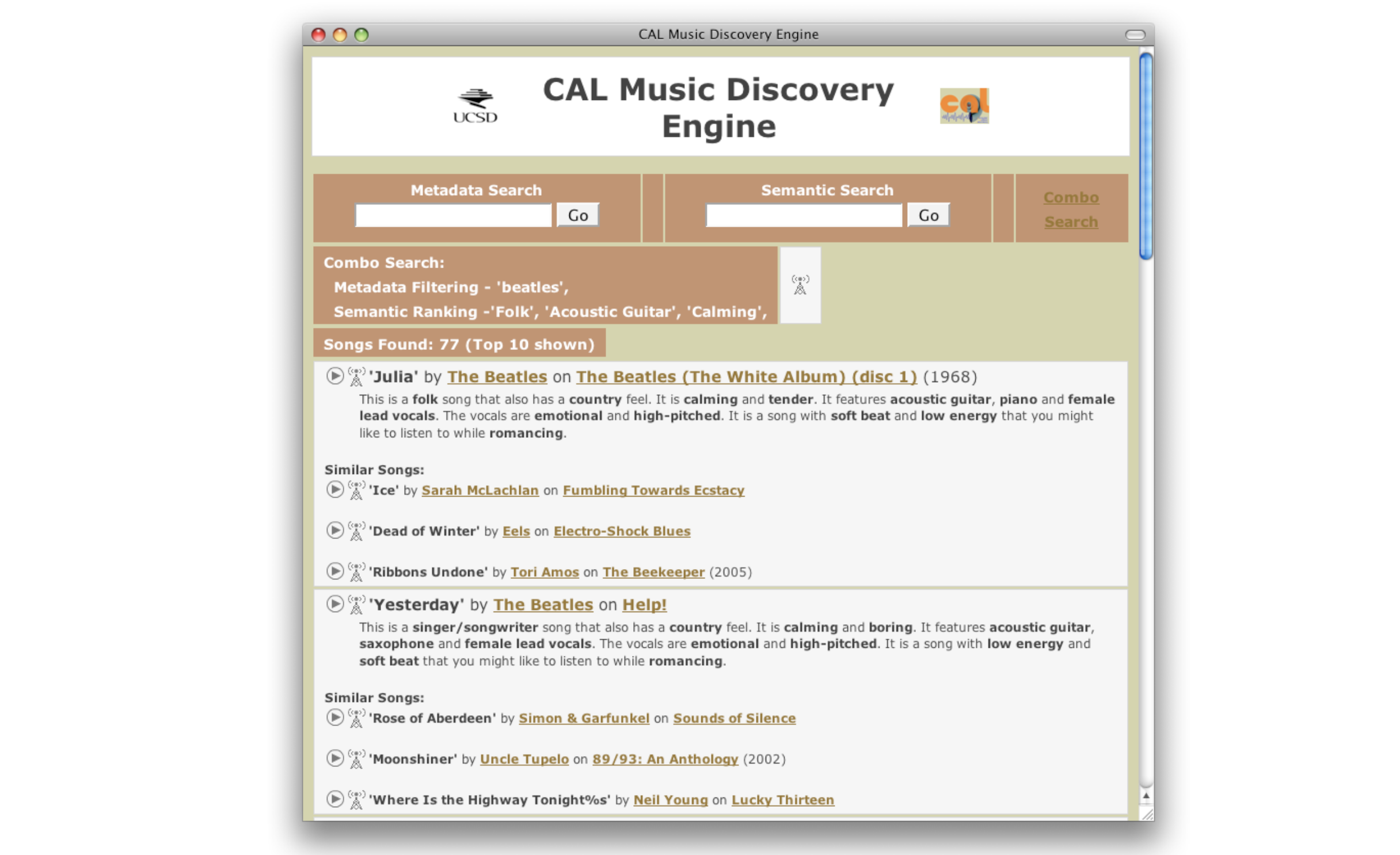
音乐检索(Music retrieval)是根据给定查询找到一组匹配音乐作品的任务。查询可以采用多种形式——可以是音乐属性描述(例如,”欢快的流行歌曲”)、元数据信息(例如,”Oasis - Don’t Look Back in Anger”)或相似性查询(例如,类似 Oasis 的音乐)。系统会分析查询并在音乐数据库中搜索,返回与搜索条件最匹配的相关结果。检索到的结果通常按照与查询的相关性或相似度进行排序。这项技术使用户能够以比传统目录浏览更加直观和灵活的方式发现音乐。音乐检索系统需要弥合高层查询描述与底层音频特征之间的语义鸿沟,这使其成为音乐信息检索(MIR)中的一个具有挑战性的问题。
早期的文本到音乐检索(Text-to-Music Retrieval)已经在”query-by-text”[TBTL08] 和”query-by-description”[Whi05] 的名称下被研究了很长时间。正如之前所解释的,最初的系统是基于监督分类方法构建的。
Note
“query-by-text” system can retrieve appropriate songs for a large number of musically relevant words. … we describe such a system and show that it can both annotate novel audio content with semantically meaningful words and retrieve relevant audio tracks from a database of unannotated tracks given a text-based query. We view the related tasks of semantic annotation and retrieval of audio as one supervised multiclass, multilabel learning problem. [TBTL08]
早期检索方法#
早期的检索方法基于监督分类模型。分类模型在标注数据集上进行训练,其中人工标注者已为音轨标记了相应的属性。每个分类器学习识别与其目标标签相关的音频特征(例如,什么使一首歌听起来像”摇滚”或像 Oasis 的歌曲)。在这种方法中,首先通过初始标注任务(如流派分类,例如”rock”、”jazz”、”classical”)和乐器识别,为音乐曲目添加相关属性注释。这些注释创建了一个可用于检索的结构化标签词汇表。
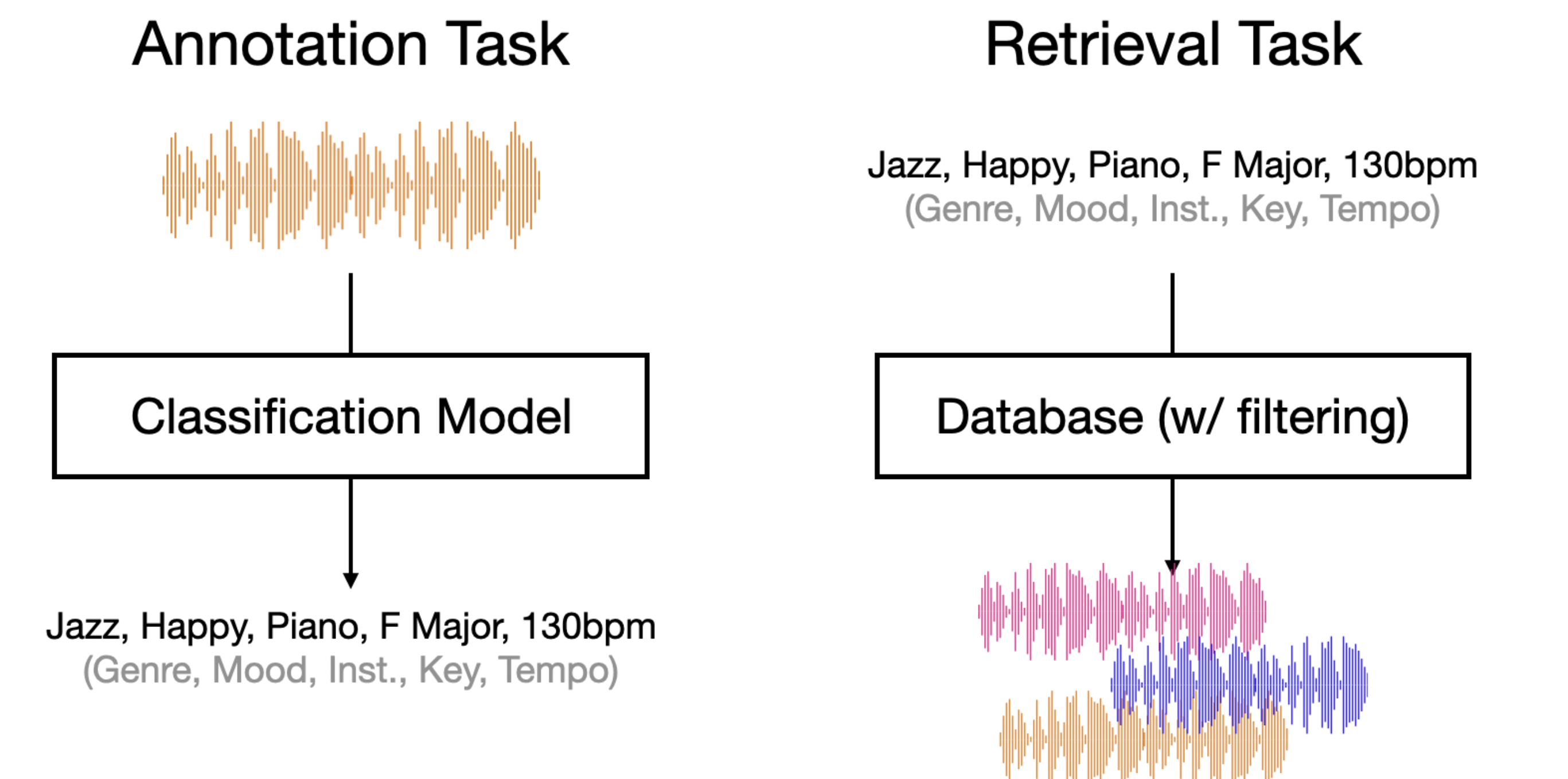
在检索阶段,有两种主要方式来搜索已标注的音乐集合:
基于过滤的布尔搜索:这种方法将每个属性视为二值过滤器。例如,查询”Oasis 的摇滚歌曲”会首先筛选标记为”rock”流派的曲目,然后从该子集中筛选标记为”Oasis”作为艺术家的曲目。多个过滤器可以使用布尔运算符(AND、OR、NOT)进行组合。
基于输出 logits 的排序:这种方法使用分类模型的输出 logits。它不仅仅使用二值的是/否过滤器,而是根据分类器最终层的原始 logit 值(softmax 之前的激活值)对曲目进行排序。这些 logit 值反映了模型在归一化之前对每个属性的评估,为曲目排序提供了更精细的评分机制。
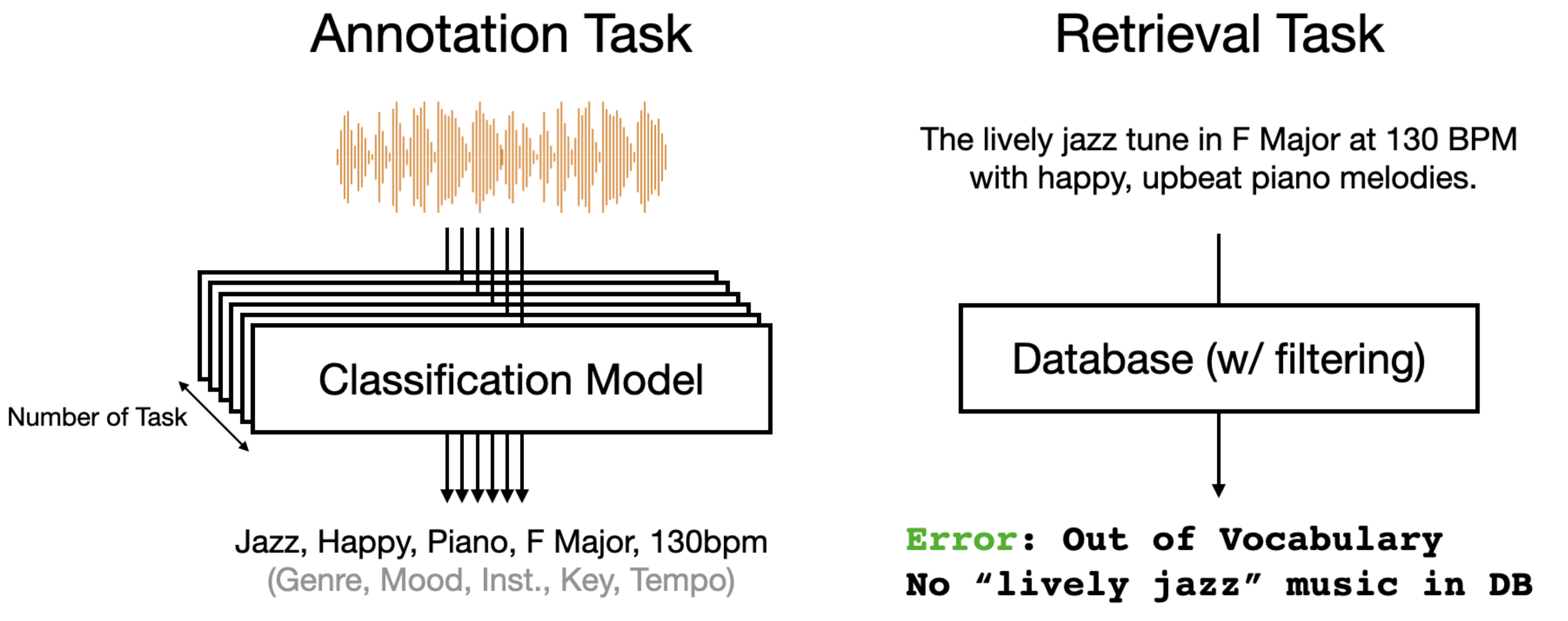
问题:词汇表外(Out of Vocabulary)#
然而,基于分类的检索框架面临两个重大挑战。首先,由于我们需要训练特定任务的分类模型,因此需要为每种不同的音乐属性(即流派分类、乐器识别、情绪检测、调性估计、节拍预测等)分别建立模型。管理多个分类器模型会导致计算开销和推理成本增加。此外,随着音乐数据库的扩展,标注成本也会成比例增长,因为每首新曲目都需要经过所有这些不同模型的处理。
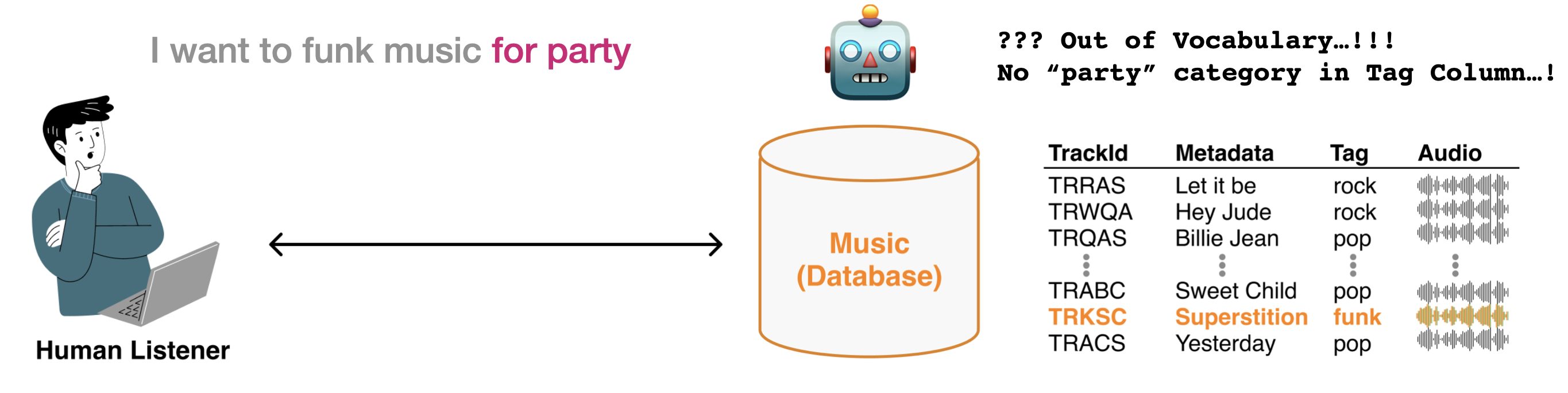
其次,在词汇覆盖方面存在一个关键限制。用于训练这些分类器的数据集通常包含非常有限的词汇表,通常仅有 50 到 200 个词。这就产生了所谓的 Out-of-Vocabulary (OOV)(词汇表外)问题——当用户尝试使用超出这个有限词汇表的术语进行搜索时,系统无法处理他们的查询。在面对更广泛的 "open vocabulary problem"(开放词汇问题)时,这一问题尤为突出,因为用户自然希望使用不受限制的语言来描述音乐。试图通过监督分类来解决这个问题,将需要开发大量不切实际的分类模型来覆盖所有可能的查询词。创建和维护这样一个全面系统的成本和复杂性,以及为每个新术语收集足够训练数据的挑战,使得这种方法在实际应用中不可行。
参考文献#
Douglas Turnbull, Luke Barrington, David Torres, and Gert Lanckriet. Semantic annotation and retrieval of music and sound effects. IEEE Transactions on Audio, Speech, and Language Processing, 16(2):467–476, 2008.
Brian Alexander Whitman. Learning the meaning of music. PhD thesis, Massachusetts Institute of Technology, 2005.