背景#
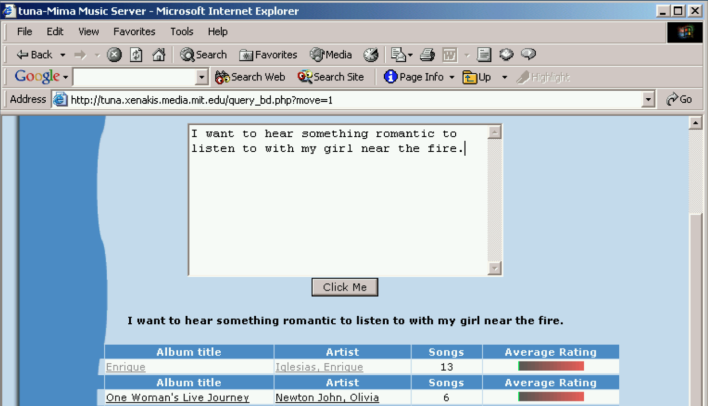
Fig. 2 Image Source: Learning the Meaning of Music by Brian A. Whitman, 2005, Massachusetts Institute of Technology(MIT)#
音乐与语言模型的探索之旅始于两个基本的人类需求:深入理解音乐,以及随时随地聆听我们想要的音乐——无论是现有艺术家的作品还是全新的创意音乐。这些根本需求推动了连接音乐与语言的技术发展。这是因为语言是我们最基本的沟通渠道,而我们正是希望通过语言来与机器进行交流。
音乐标注与检索的早期阶段#
最初的方法是监督分类(Supervised Classification)。该方法通过开发模型来为给定的音频输入预测合适的自然语言标签(固定词汇表)。这些标签可以涵盖广泛的音乐属性,包括流派、情绪、风格、乐器、用途、主题、调性、节奏等 [SLC07]。监督分类的优势在于它实现了标注过程的自动化。随着音乐数据库中标注信息的不断丰富,在检索阶段,可以使用级联过滤器更方便地找到目标音乐。此外,也可以利用监督学习的输出 logits 来找到与给定词语最接近的音乐曲目 [ELBMG07] [Lam08] [TBTL08]。监督分类的研究随时间不断演进。在2000年代初期,随着模式识别方法的进步,研究重点主要集中在特征工程(feature engineering)上 [FLTZ10]。进入2010年代后,随着深度学习的兴起,研究重心转向了模型工程(model engineering)[NCL+18]。
然而,监督分类存在两个根本性的局限。首先,它仅支持使用固定标签进行音乐理解和搜索。这意味着模型无法处理未见过的词汇。其次,语言标签通过 one-hot 编码表示,这意味着模型无法捕捉不同语言标签之间的关系。因此,训练后的模型只能针对给定的监督信号进行学习,限制了其泛化能力和对广泛音乐语言的理解能力。
音乐生成的早期阶段#
相比于相对容易建模的判别模型(Discriminative Models)\(p(y|x)\),需要对数据分布进行建模的生成模型(Generative Models)\(p(x|c)\) 在早期阶段主要专注于生成短小的单乐器片段或语音数据集,而非复杂的多轨音乐。在早期阶段,研究者探索了无条件生成 \(p(x)\) 方法,包括基于似然的模型(以 WaveNet [VDODZ+16] 和 SampleRNN [MKG+16] 为代表)以及对抗模型(以 WaveGAN [DMP19] 为代表)。
早期的条件生成模型 \(p(x|c)\) 包括 Universal Music Translation Network [MWPT19](使用单一共享编码器和针对不同乐器条件的不同解码器)以及 NSynth [ERR+17](在 WaveNet 自编码器中加入了音高条件)。这些模型代表了可控音乐生成的首批尝试。
然而,在这一阶段,能够以自然语言作为条件的生成模型尚未出现。尽管生成具有长期一致性的高质量音频仍然是一个挑战,但这些早期模型为音乐生成技术的未来发展奠定了基础。
参考文献#
Chris Donahue, Julian McAuley, and Miller Puckette. Adversarial audio synthesis. In International Conference on Learning Representations (ICLR). 2019.
Douglas Eck, Paul Lamere, Thierry Bertin-Mahieux, and Stephen Green. Automatic generation of social tags for music recommendation. Advances in neural information processing systems, 2007.
Jesse Engel, Cinjon Resnick, Adam Roberts, Sander Dieleman, Mohammad Norouzi, Douglas Eck, and Karen Simonyan. Neural audio synthesis of musical notes with wavenet autoencoders. In International Conference on Machine Learning. PMLR, 2017.
Zhouyu Fu, Guojun Lu, Kai Ming Ting, and Dengsheng Zhang. A survey of audio-based music classification and annotation. IEEE transactions on multimedia, 2010.
Paul Lamere. Social tagging and music information retrieval. Journal of new music research, 2008.
Soroush Mehri, Kundan Kumar, Ishaan Gulrajani, Rithesh Kumar, Shubham Jain, Jose Sotelo, Aaron Courville, and Yoshua Bengio. Samplernn: an unconditional end-to-end neural audio generation model. arXiv preprint arXiv:1612.07837, 2016.
Noam Mor, Lior Wolf, Adam Polyak, and Yaniv Taigman. A universal music translation network. In International Conference on Learning Representations (ICLR). 2019.
Juhan Nam, Keunwoo Choi, Jongpil Lee, Szu-Yu Chou, and Yi-Hsuan Yang. Deep learning for audio-based music classification and tagging: teaching computers to distinguish rock from bach. IEEE signal processing magazine, 2018.
Mohamed Sordo, Cyril Laurier, and Oscar Celma. Annotating music collections: how content-based similarity helps to propagate labels. In ISMIR, 531–534. 2007.
Douglas Turnbull, Luke Barrington, David Torres, and Gert Lanckriet. Semantic annotation and retrieval of music and sound effects. IEEE Transactions on Audio, Speech, and Language Processing, 16(2):467–476, 2008.
Aaron Van Den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, Koray Kavukcuoglu, and others. Wavenet: a generative model for raw audio. arXiv preprint arXiv:1609.03499, 2016.