模型#
用于基于自然语言的音乐描述的深度学习模型通常属于以下两种设计之一:
Encoder-decoder(编码器-解码器)模型
在 Table 1 中,我们概述了从 2016 年至今的音乐描述模型。* 标记的任务不属于音乐描述范畴,但仍由该模型处理。
Model |
Type |
Task(s) |
Weights |
Training dataset |
|---|---|---|---|---|
Choi et al. [MBQF21] |
Encoder-decoder |
Captioning (playlist) |
❌ |
Private data |
MusCaps [MBQF21] |
Encoder-decoder |
Captioning, retrieval* |
❌ |
Private data |
PlayNTell [GHE22] |
Encoder-decoder |
Captioning (playlist) |
✅ link |
PlayNTell |
LP-MusicCaps [MBQF21] |
Encoder-decoder |
Captioning |
✅ link |
LP-MusicCaps |
ALCAP [HHL+23] |
Encoder-decoder |
Captioning |
❌ |
Song Interpretation Dataset, NetEase Cloud Music Review Dataset |
BLAP [LPPW24] |
Adapted LLM |
Captioning |
✅ link |
Shutterstock (31k clips) |
LLark [GDSB23] |
Adapted LLM |
Captioning, MQA |
❌ |
MusicCaps, YouTube8M-MusicTextClips, MusicNet, FMA, MTG-Jamendo, MagnaTagATune |
MU-LLaMA [LHSS24] |
Adapted LLM |
Captioning, MQA |
✅ link |
MusicQA |
MusiLingo [DML+24] |
Adapted LLM |
Captioning, MQA |
✅ link |
MusicInstruct |
M2UGen[HLSS23] |
Adapted LLM |
Captioning, MQA, music generation |
✅ link |
MUCaps, MUEdit |
OpenMU [ZZM+24] |
Adapted LLM |
Captioning, MQA |
✅ link |
MusicCaps, YouTube8M-MusicTextClips, MusicNet, FMA, MTG-Jamendo, MagnaTagATune |
FUTGA [WNN+24] |
Adapted LLM |
Captioning (fine-grained) |
✅ link |
FUTGA |
Encoder-Decoder 模型#
这是最早的深度学习 music captioning 模型所采用的建模框架。 Encoder-decoder 模型最初出现在序列到序列任务(如机器翻译)的背景下。不难看出,许多任务都可以被转化为序列到序列问题,因此 encoder-decoder 模型首先在图像字幕生成中得到广泛应用,随后很快被用于音频字幕生成,包括音乐领域。
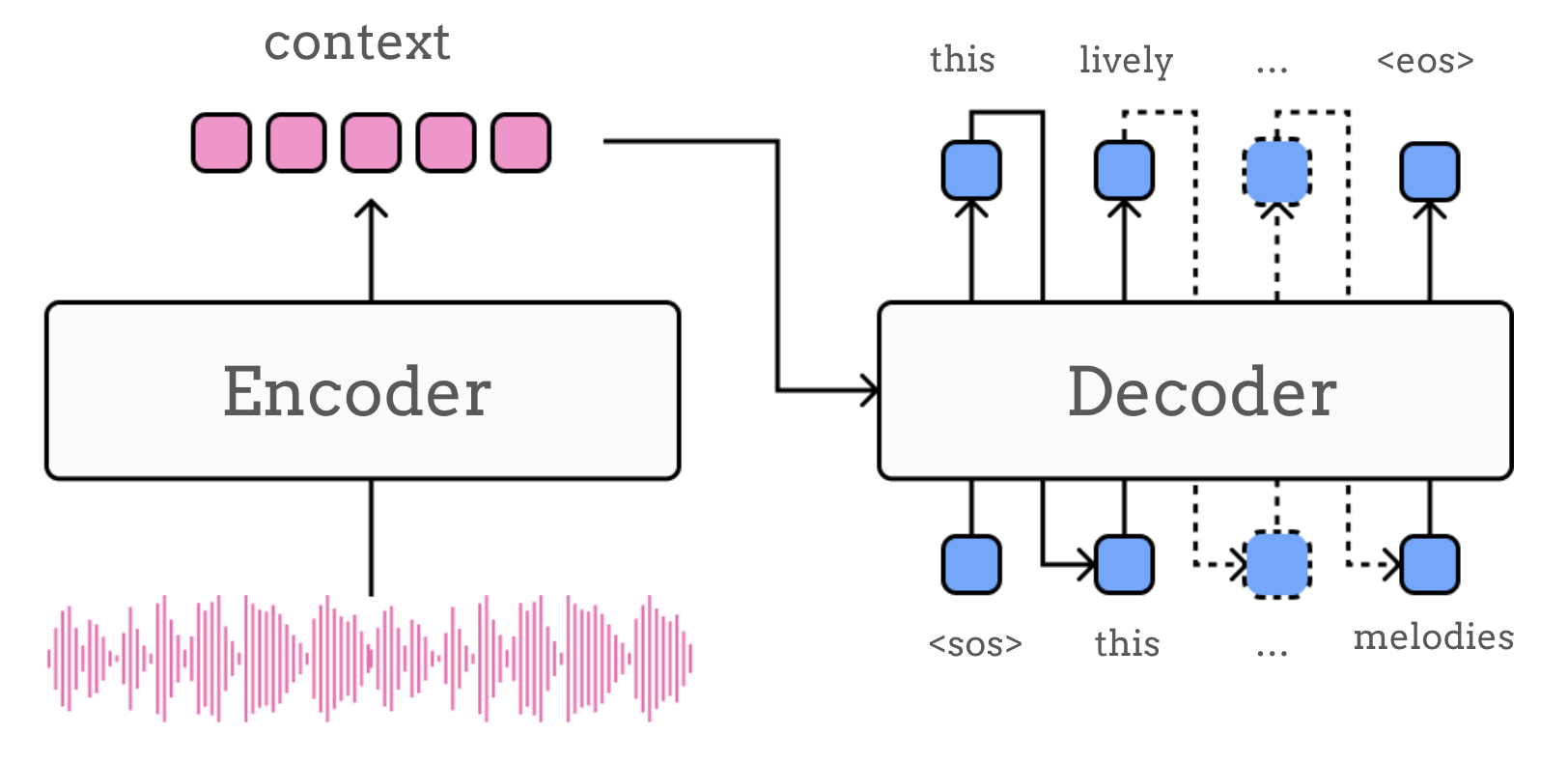
顾名思义,此类模型由两个主要模块组成:encoder(编码器)和 decoder(解码器)。尽管存在多种变体,但在最简单的设计中,encoder 负责将输入序列(即音频输入)处理为中间表示(上下文 \(c\)):
然后 decoder 将这一表示”展开”为目标序列(例如描述音频输入的文本),通常在序列的每一步计算可能 token 的概率分布,以上下文 \(c\) 为条件:
架构#
在 encoder 和 decoder 组件的设计方面,一般原则是采用各自模态的最先进架构,在特定领域限制(例如需要在音乐信号中捕捉不同时间尺度的特征)的要求与我们可用的计算和数据资源之间取得平衡。这意味着理论上 encoder-decoder 音乐字幕生成模型有许多可能的设计,但大多数都遵循标准选择。下面我们回顾其中一些。
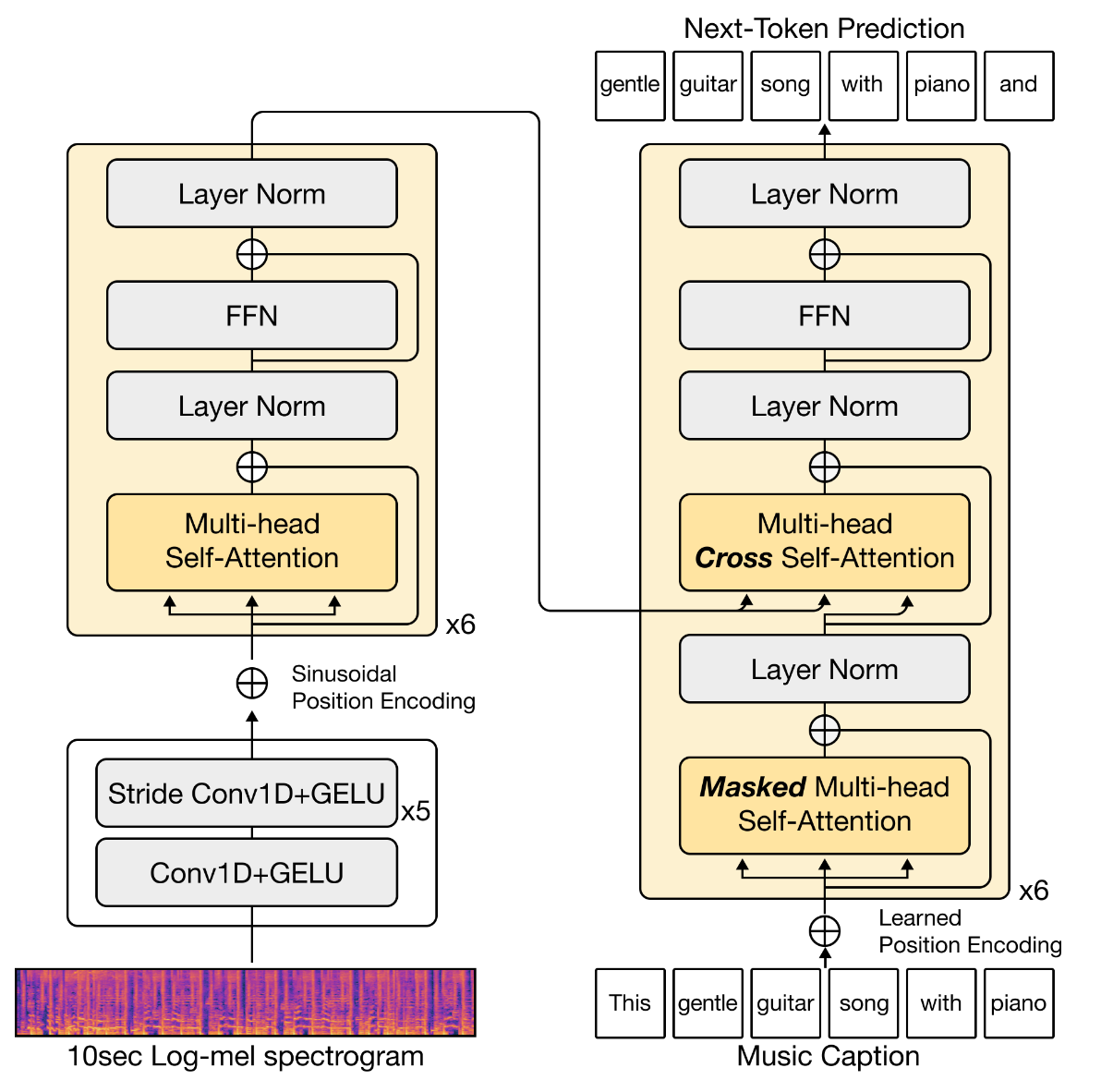
第一个 encoder-decoder 音乐描述模型出现在 Choi et al. [CFS16] 的工作中。虽然该模型尚未能生成格式良好的句子,但 Manco et al. 后来提出的 MusCaps [MBQF21] 巩固了类似架构在轨道级 music captioning 中的使用。这些早期的 encoder-decoder 音乐字幕生成模型采用基于 CNN 的音频编码器和基于 RNN 的语言解码器。该框架的更新迭代版本通常使用基于 Transformer 的语言解码器(例如基于 GPT-2 [GHE22] 或 BART [DCLN23] 等 Transformer decoder),搭配 CNN [GHE22] 或 Transformer 音频编码器 [SCDBK24],有时还结合两者 [DCLN23]。
条件机制与融合#
我们已经讨论了如何选择 encoder 和 decoder,那么如何将两者连接起来以实现两种模态之间的转换呢?当然,将 encoder 的输出传递给 decoder 有标准的方法,但由于我们处理的是不同的模态,这比通常需要更多注意。用于将语言生成以音频输入为条件的机制类型,实际上是不同 encoder-decoder 模型之间的一个关键区别。在实践中,这一选择与 encoder 和 decoder 模块的网络架构密切相关。在最简单的情况下,encoder 为整个输入序列输出一个固定大小的 embedding,我们称之为 \(\boldsymbol{a}\),而 decoder(例如 RNN)以此 embedding 进行初始化。更准确地说,RNN 的初始状态 \(\boldsymbol{h}_0\) 被设置为 encoder 的输出,或其(非)线性投影:
然而在大多数情况下,我们使用更复杂的架构,条件机制通过音频和文本表示的**融合(fusion)**来实现。 早期使用基于 RNN 的文本解码器的模型采用了多种融合机制,如特征拼接或跨模态 attention [MBQF21]。在 RNN 中,拼接作为模态融合机制通常是将音频 embedding(例如 encoder 模块的输出 \(\boldsymbol{a}\))与输入 \(\boldsymbol{x}\) 拼接,使 RNN 状态 \(\boldsymbol{h}\) 依赖于 \([\boldsymbol{a}; \boldsymbol{x}]\),或与前一状态向量拼接 \([\boldsymbol{a}; \boldsymbol{h}_{t-1}]\),有时两者兼用。在这种情况下,我们假设 encoder 产生单个音频 embedding。
如果我们的 encoder 产生的是一系列音频 embedding,并且我们希望保留条件信号的序列特性,一种替代的融合方式是通过 cross-attention(交叉注意力)。在这种情况下,我们不再在每个时间步 \(t\) 拼接相同的音频 embedding,而是计算注意力分数 \(\beta_{t i}\),以在每个时间步 \(t\) 对音频序列中的每个元素 \(\boldsymbol{a}_i\) 赋予不同的权重:
其中注意力分数由以下公式给出:
\(e_{t i}\) 的具体计算取决于所使用的评分函数。例如,可以有:
其中 \(\boldsymbol{w}_{a t t}\) 和 \(\boldsymbol{W}^{a t t}\) 是可学习参数。
类似的基于 attention 的融合方式也可用于基于 Transformer 的架构 [GHE22] [DCLN23]。在这种设置下,除了上述的 cross-attention 外,融合还可以直接嵌入到 Transformer 块中,通过修改其 self-attention 机制使其同时依赖于文本和音频 embedding,尽管 co-attentional Transformer 层的具体实现在不同模型之间有所不同:
除了所使用的融合机制类型外,根据模态组合的层级,通常还可以区分早期融合(即在输入层面)、中间融合(在整个处理流程中某个中间步骤产生的潜在表示层面)或晚期融合(即在输出层面)。需要注意的是,早期、中间和晚期融合这些术语并没有统一的定义,在不同的工作中使用方式略有不同。
多模态自回归模型#
大语言模型(LLM)的成功在近年来极大地影响了音乐描述的发展。因此,当今最先进的模型都在某种程度上依赖于 LLM。通常,这意味着音乐描述系统密切模仿基于 Transformer 的纯文本自回归建模,但在此框架内有两条主要路径可以选择。第一条也是最常见的路径是适配纯文本 LLM,通过增加额外的建模组件使其成为多模态模型。我们称这些为 adapted LLM(经过适配的 LLM)。第二种选择是从一开始就将音频和文本视为 token 序列,设计分词技术并在多种模态上进行训练,而无需额外的模态特定组件。这两种方法之间的界限并不总是清晰的。在下一节中,我们尝试更好地定义适配于音乐-语言输入的 LLM 的显著特征,并勾勒出原生多模态模型的新趋势及其在音乐描述中的潜力。
总的来说,这一研究方向的共同主线是试图通过将所有多模态任务重新表述为文本生成来统一它们。当在音乐数据上训练时,多模态 LLM 可以利用其基于文本的接口来支持各种音乐理解和描述任务,只需允许用户通过文本查询并获取关于给定音频输入的信息。这正是实现我们在任务章节中看到的基于对话的音乐描述任务的机制。
Adapted LLM(经过适配的 LLM)#
在音频描述(包括音乐)中,一种特别流行的建模范式是 adapted(多模态)LLM。这种方法的核心是一个预训练的纯文本 LLM,它被适配为能够接收不同模态的输入,例如音频。这通过一个 adapter(适配器)模块实现——一个轻量级神经网络,经过训练将音频特征提取器(通常是预训练后冻结的)产生的 embedding 映射到 LLM 的输入空间。经过这一适配过程,LLM 就可以同时接收音频 embedding 和文本 embedding。
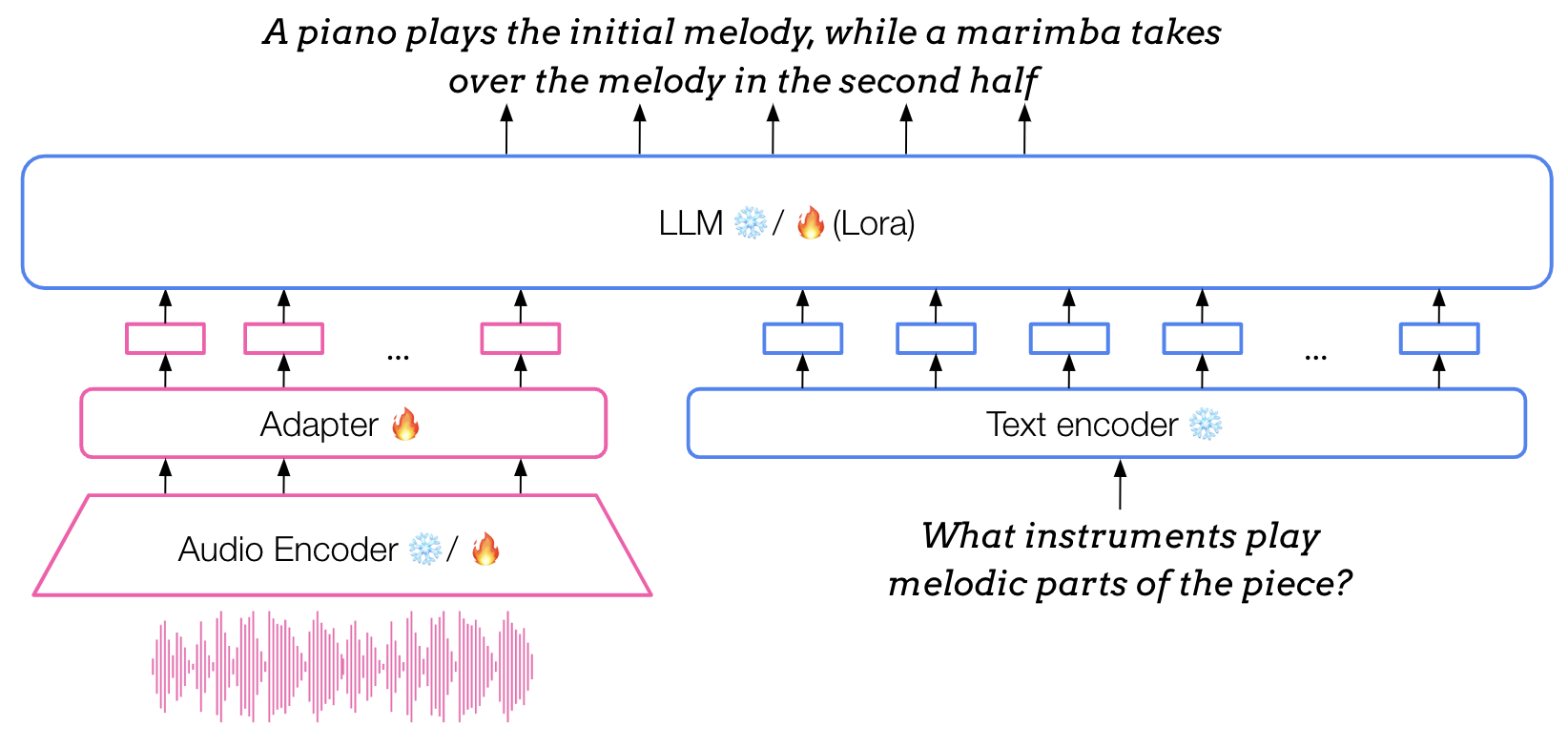
在用于音乐的 adapted LLM 中,adapter 模块的架构通常由轻量级的 MLP(2到3个隐藏层)或 Q-Former 组成。在通用音频 adapted LLM(或视觉领域的类似模型)中使用的其他架构还包括更复杂的设计,如 Gated XATTN dense layers。这篇关于 Visual Language Models 的博客文章对这些进行了更详细的介绍。
从训练的角度来看,与纯文本设置类似,adapted LLM 的训练通常分为多个阶段。在纯文本部分的预训练和微调之后,其余组件经历一系列多模态训练阶段,同时骨干 LLM 要么保持冻结,要么进一步微调。这些步骤通常是多任务预训练和有监督微调的组合,通常还包括指令微调(instruction tuning),所有这些都在音频和文本配对数据上进行。
除了 Table 1 中专门面向音乐的多模态 LLM 外,具有通用音频理解能力的 LLM 同样可以执行 captioning 和 MQA 等音乐描述任务。其中包括:
原生多模态自回归模型#
Adapted LLM 可以相对高效地将纯文本 LLM 转化为多模态模型:根据本节讨论的模型,适配阶段的训练大约需要 2万到15万个音频-文本配对样本,而多模态预训练则需要多出几个数量级的数据。然而,这也限制了它们的性能,往往导致对语言模态的偏向以及较差的音频和音乐理解能力 [WMB+24]。一种有望克服这一局限的替代方案是采用原生多模态的自回归建模方法。一个关键区别在于,adapted LLM 需要模态特定的编码器(通常是单独预训练的),而原生多模态 LLM 则放弃这些,转而采用统一的分词方案,从一开始就将音频 token 像文本 token 一样处理。 这一范式有时被称为混合模态早期融合建模(mixed-modal early-fusion modelling)。
值得注意的是,目前这类模型对于音乐描述来说是一个有前景的方向,而非完全成熟的范式。目前尚不存在专门面向音乐的多模态自回归 Transformer 模型,但一些通用模型,如 AnyGPT [ZDY+24],在其训练和评估中包含了音乐领域的数据。这与开发覆盖所有领域的大规模模型的总体趋势一致,但这一建模范式在未来几年对音乐描述的影响仍有待观察。
参考文献#
Keunwoo Choi, George Fazekas, and Mark Sandler. Towards music captioning: generating music playlist descriptions. In Extended abstracts for the Late-Breaking Demo Session of the 17th International Society for Music Information Retrieval Conference. 08 2016. doi:10.48550/arXiv.1608.04868.
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models. December 2023. arXiv:2311.07919 [cs, eess]. URL: http://arxiv.org/abs/2311.07919 (visited on 2024-02-26), doi:10.48550/arXiv.2311.07919.
Zihao Deng, Yinghao Ma, Yudong Liu, Rongchen Guo, Ge Zhang, Wenhu Chen, Wenhao Huang, and Emmanouil Benetos. MusiLingo: Bridging Music and Text with Pre-trained Language Models for Music Captioning and Query Response. In Kevin Duh, Helena Gomez, and Steven Bethard, editors, Findings of the Association for Computational Linguistics: NAACL 2024, 3643–3655. Mexico City, Mexico, June 2024. Association for Computational Linguistics. URL: https://aclanthology.org/2024.findings-naacl.231 (visited on 2024-07-04).
Soham Deshmukh, Benjamin Elizalde, Rita Singh, and Huaming Wang. Pengi: An Audio Language Model for Audio Tasks. In Thirty-seventh Conference on Neural Information Processing Systems. 2023. arXiv:2305.11834 [cs, eess]. URL: http://arxiv.org/abs/2305.11834 (visited on 2024-02-16), doi:10.48550/arXiv.2305.11834.
SeungHeon Doh, Keunwoo Choi, Jongpil Lee, and Juhan Nam. Lp-musiccaps: llm-based pseudo music captioning. In International Society for Music Information Retrieval (ISMIR). 2023.
Giovanni Gabbolini, Romain Hennequin, and Elena Epure. Data-efficient playlist captioning with musical and linguistic knowledge. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors, Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 11401–11415. Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. URL: https://aclanthology.org/2022.emnlp-main.784, doi:10.18653/v1/2022.emnlp-main.784.
Josh Gardner, Simon Durand, Daniel Stoller, and Rachel M Bittner. Llark: a multimodal foundation model for music. arXiv preprint arXiv:2310.07160, 2023.
Yuan Gong, Hongyin Luo, Alexander H Liu, Leonid Karlinsky, and James Glass. Listen, think, and understand. arXiv preprint arXiv:2305.10790, 2023.
Zihao He, Weituo Hao, Wei-Tsung Lu, Changyou Chen, Kristina Lerman, and Xuchen Song. Alcap: alignment-augmented music captioner. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 16501–16512. 2023.
Atin Sakkeer Hussain, Shansong Liu, Chenshuo Sun, and Ying Shan. M2UGen: Multi-modal Music Understanding and Generation with the Power of Large Language Models. arXiv preprint arXiv:2311.11255, 2023.
Zhifeng Kong, Arushi Goel, Rohan Badlani, Wei Ping, Rafael Valle, and Bryan Catanzaro. Audio flamingo: a novel audio language model with few-shot learning and dialogue abilities. In ICML. 2024. URL: https://openreview.net/forum?id=WYi3WKZjYe.
Luca A Lanzendorfer, Nathanal Perraudin, Constantin Pinkl, and Roger Wattenhofer. BLAP: Bootstrapping Language-Audio Pre-training for Music Captioning. In Workshop on AI-Driven Speech, Music, and Sound Generation. 2024.
Dongting Li, Chenchong Tang, and Han Liu. Audio-llm: activating theâ capabilities ofâ large language models toâ comprehend audio data. In Xinyi Le and Zhijun Zhang, editors, Advances in Neural Networks – ISNN 2024, 133–142. Singapore, 2024. Springer Nature Singapore.
Shansong Liu, Atin Sakkeer Hussain, Chenshuo Sun, and Ying Shan. Music understanding llama: advancing text-to-music generation with question answering and captioning. In ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), volume, 286–290. 2024. doi:10.1109/ICASSP48485.2024.10447027.
Ilaria Manco, Emmanouil Benetos, Elio Quinton, and György Fazekas. Muscaps: generating captions for music audio. In 2021 International Joint Conference on Neural Networks (IJCNN), 1–8. IEEE, 2021.
Nikita Srivatsan, Ke Chen, Shlomo Dubnov, and Taylor Berg-Kirkpatrick. Retrieval guided music captioning via multimodal prefixes. In Kate Larson, editor, Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24, 7762–7770. International Joint Conferences on Artificial Intelligence Organization, 8 2024. AI, Arts & Creativity. URL: https://doi.org/10.24963/ijcai.2024/859, doi:10.24963/ijcai.2024/859.
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. SALMONN: Towards Generic Hearing Abilities for Large Language Models. In The Twelfth International Conference on Learning Representations. October 2023. URL: https://openreview.net/forum?id=14rn7HpKVk (visited on 2024-02-22).
Benno Weck, Ilaria Manco, Emmanouil Benetos, Elio Quinton, George Fazekas, and Dmitry Bogdanov. MuChoMusic: Evaluating Music Understanding in Multimodal Audio-Language Models. In 25th International Society for Music Information Retrieval Conference. August 2024. arXiv:2408.01337 [cs, eess]. URL: http://arxiv.org/abs/2408.01337 (visited on 2024-08-21), doi:10.48550/arXiv.2408.01337.
Junda Wu, Zachary Novack, Amit Namburi, Jiaheng Dai, Hao-Wen Dong, Zhouhang Xie, Carol Chen, and Julian McAuley. Futga: towards fine-grained music understanding through temporally-enhanced generative augmentation. arXiv preprint arXiv:2407.20445, 2024.
Jun Zhan, Junqi Dai, Jiasheng Ye, Yunhua Zhou, Dong Zhang, Zhigeng Liu, Xin Zhang, Ruibin Yuan, Ge Zhang, Linyang Li, Hang Yan, Jie Fu, Tao Gui, Tianxiang Sun, Yu-Gang Jiang, and Xipeng Qiu. AnyGPT: unified multimodal LLM with discrete sequence modeling. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 9637–9662. Bangkok, Thailand, August 2024. Association for Computational Linguistics. URL: https://aclanthology.org/2024.acl-long.521, doi:10.18653/v1/2024.acl-long.521.
Mengjie Zhao, Zhi Zhong, Zhuoyuan Mao, Shiqi Yang, Wei-Hsiang Liao, Shusuke Takahashi, Hiromi Wakaki, and Yuki Mitsufuji. Openmu: your swiss army knife for music understanding. arXiv preprint arXiv:2410.15573, 2024.