模型#
音乐检索系统已经从简单的分类方法发展到能够处理自然语言查询的更复杂方法。音频-文本联合嵌入(Audio-text joint embedding)代表了该领域的重大进步,为音乐与文本描述的匹配提供了强大的框架。这种基于多模态深度度量学习的方法,使用户能够使用灵活的自然语言描述来搜索音乐,而不受限于预定义的类别。通过将音频内容和文本描述投射到共享的嵌入空间(embedding space)中,系统可以高效地计算音乐与文本之间的相似度,从而实现根据任意文本查询检索最匹配音乐的功能。
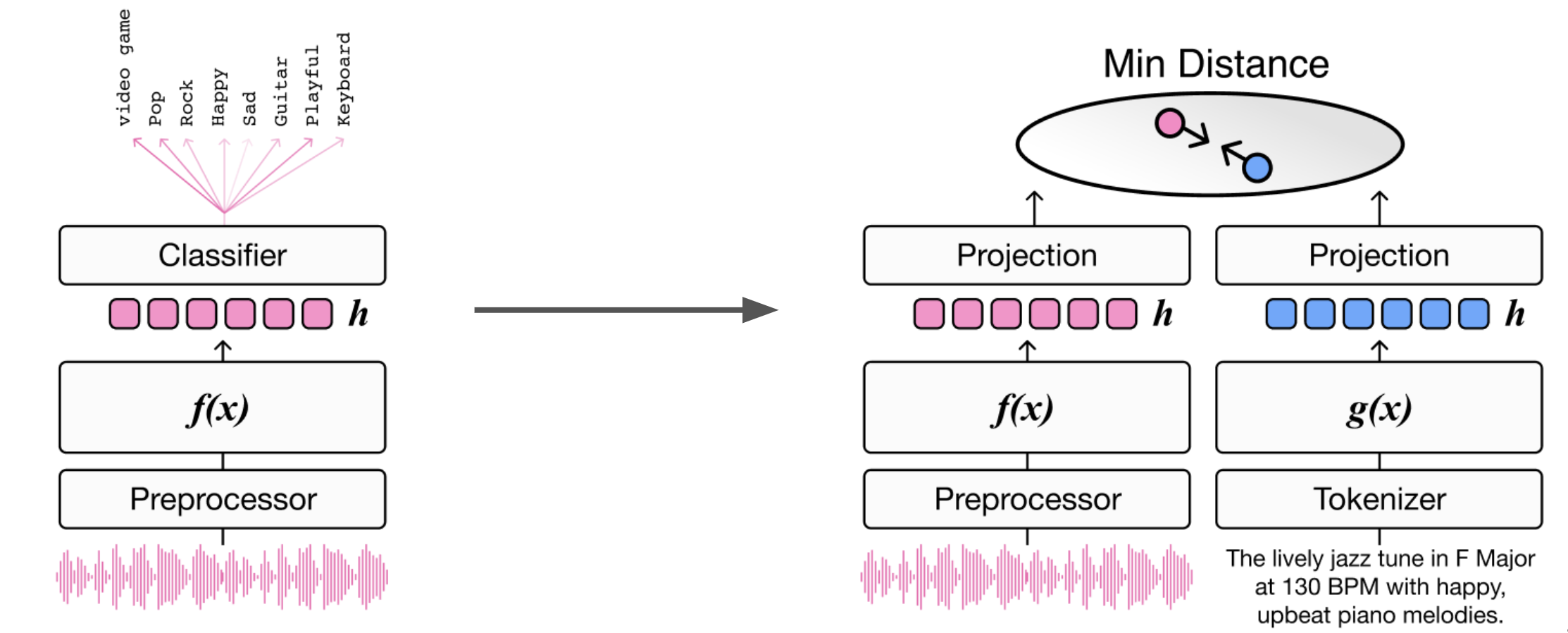
多模态联合嵌入模型架构#
从高层来看,联合嵌入模型(joint embedding model)使用配对的文本和音频样本进行训练。模型学习将语义相关的配对映射到共享嵌入空间中相近的位置,同时将不相关的样本推开。这样就创建了一种有意义的几何排列,其中嵌入之间的距离反映了它们的语义相似度。
令 \(x_{a}\) 表示一个音乐音频样本,\(x_{t}\) 表示其配对的文本描述。函数 \(f(\cdot)\) 和 \(g(\cdot)\) 分别表示音频编码器和文本编码器,通常实现为深度神经网络。音频编码器处理原始音频波形或频谱图以提取相关的声学特征,而文本编码器将文本描述转换为密集向量表示。每个编码器输出的特征嵌入随后通过投影层映射到共享的协同嵌入空间(co-embedding space),以对齐嵌入的维度和尺度。在训练过程中,模型通常使用基于铰链间隔的 triplet loss(三元组损失)或基于交叉熵的 contrastive loss(对比损失)来学习这些映射。这些损失函数鼓励模型最小化正样本对之间的距离,同时最大化负样本对之间的距离,从而有效地塑造嵌入空间的结构。
度量学习损失函数#
用于训练联合嵌入模型的最常见度量学习损失函数是 triplet loss 和 contrastive loss。
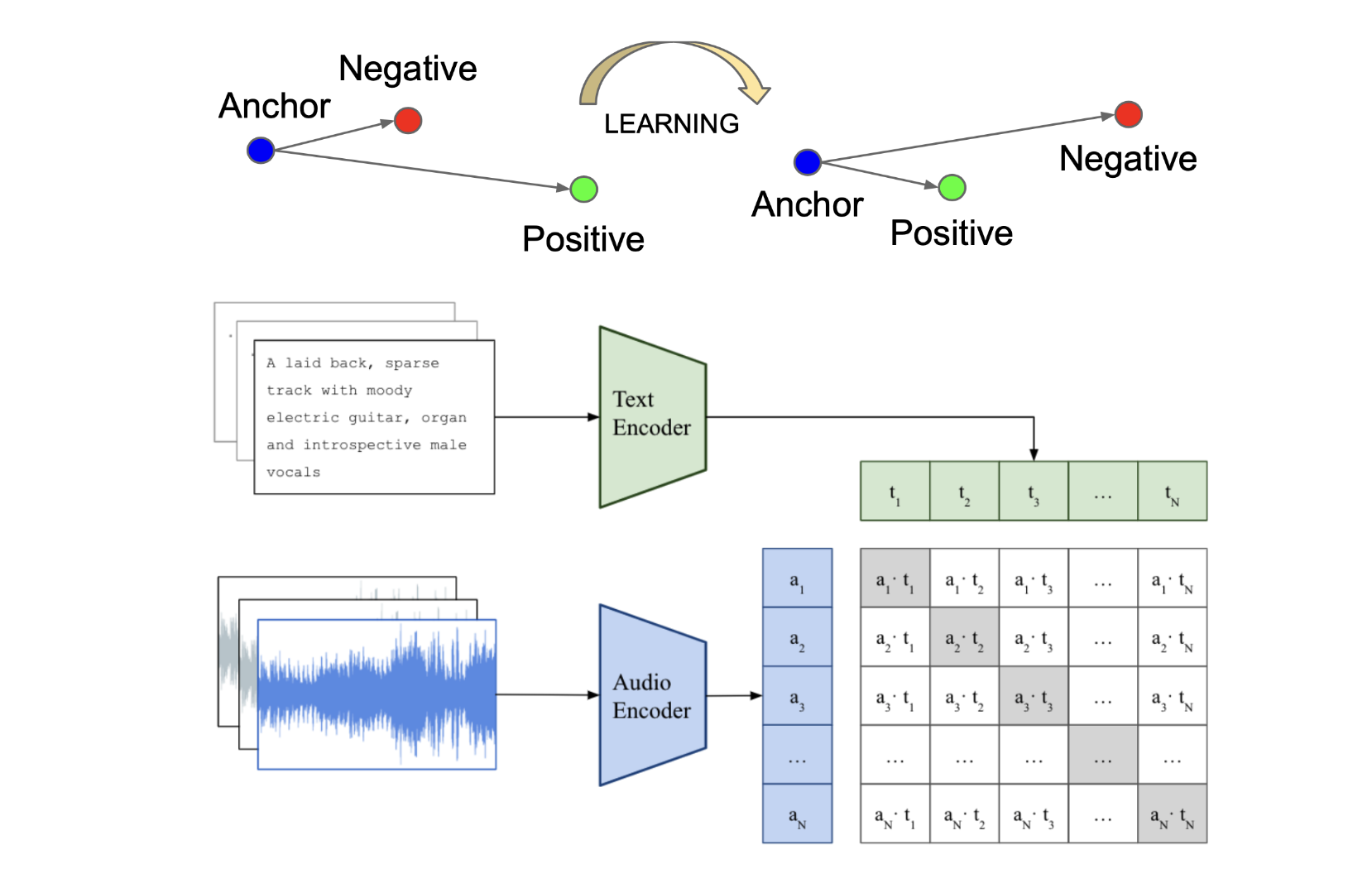
triplet loss 模型的目标是学习一个嵌入空间,使得语义相关的输入对在潜在空间中的映射比不相关的对更接近。对于每个训练样本,模型接收一个锚定音频输入、一个与该音频匹配的正文本描述以及一个不相关的负文本描述。目标函数表述如下:
其中 \(\delta\) 是控制正负样本对之间最小距离的间隔超参数,\(f(x_{a})\) 是锚定样本的音频嵌入,\(g(x_{t}^{+})\) 是正描述的文本嵌入,\(g(x_{t}^{-})\) 是负描述的文本嵌入。点积用于衡量嵌入之间的相似度。损失函数鼓励锚定样本与正样本对之间的相似度比锚定样本与负样本对之间的相似度至少大 \(\delta\)。
contrastive loss 模型的核心思想是在整个 mini-batch 样本中减小正样本对之间的距离,同时增大负样本对之间的距离。与每个锚点只使用一个负样本的 triplet loss 不同,contrastive loss 模型利用大小为 \(N\) 的 mini-batch 中存在的多个负样本。在训练过程中,音频编码器和文本编码器被联合优化,以最大化 \(N\) 个正(音乐,文本)配对的相似度,同时最小化 \(N \times (N-1)\) 个负配对的相似度。这种方法被称为 InfoNCE 损失的多模态版本 [OLV18],[RKH+21],通过同时考虑多个负样本实现了更高效的训练。损失函数表述如下:
其中 \(\tau\) 是一个可学习的参数。
联合嵌入的优势是什么?#
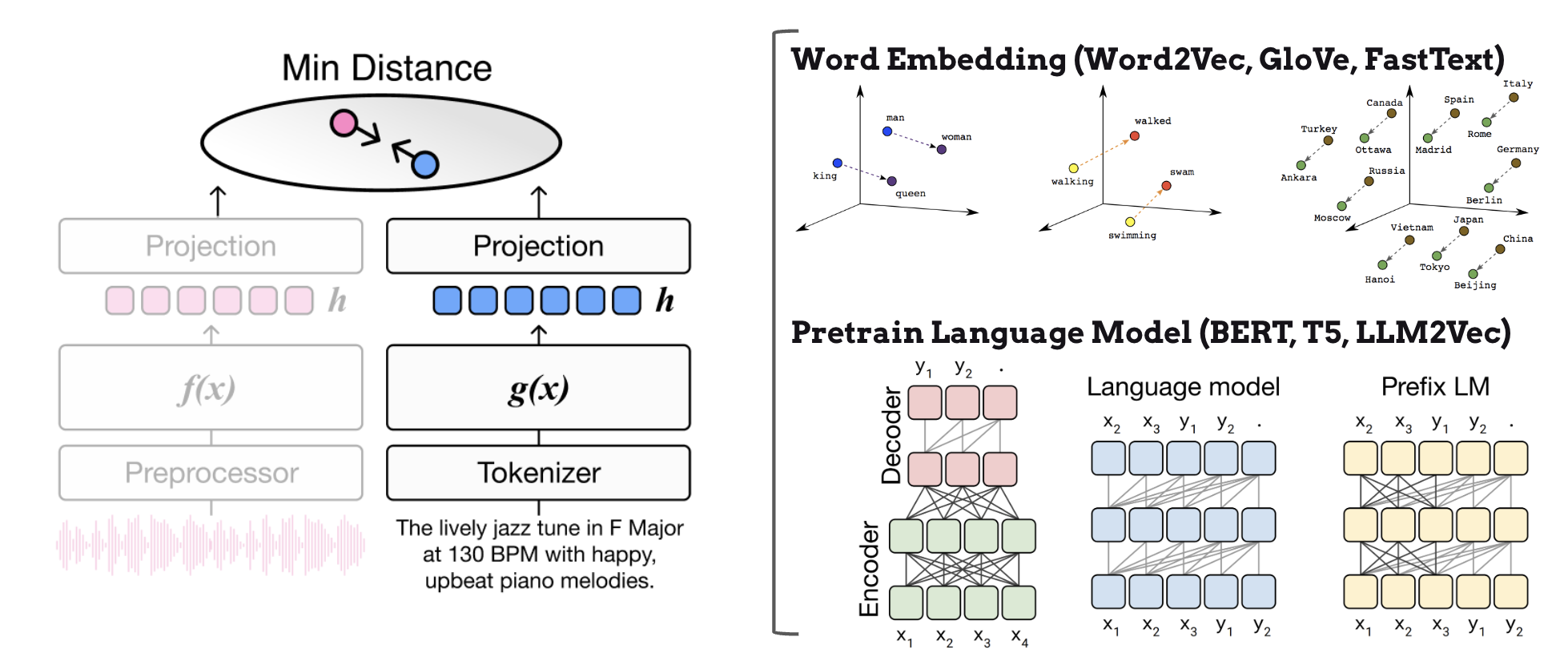
联合嵌入的关键优势在于,它允许我们利用预训练语言模型的嵌入空间作为监督信号,而不是受限于固定的词汇表。预训练语言模型在互联网上的大规模文本语料库上训练,有效地编码了词汇和短语之间丰富的语义关系。这使得音乐检索系统能够通过利用这些全面的语言表示来高效处理零样本(zero-shot)用户查询,这些表示捕获了细微的含义和关联。
此外,通过引入语言模型编码器,我们可以借助先进的子词分词技术(如 byte-pair encoding(BPE)或 sentence-piece encoding)有效地解决词汇表外问题。这些分词方法能够智能地将未知词拆分为模型词汇表中已有的更小子词单元。例如,如果用户查询一个不熟悉的艺术家名字”Radiohead”,分词器可能会将其拆分为”radio”+”head”,使系统能够根据其组成部分来处理和理解这个新词。
预训练语言模型语义和子词分词的强大组合提供了两个关键优势:
通过语言模型表示灵活处理开放词汇查询——系统可以利用预训练语言模型中编码的丰富语义知识来理解和处理几乎无限范围的自然语言描述
通过子词分词稳健处理词汇表外的词——即使是完全新颖或罕见的术语,也可以通过将其拆分为有意义的子词组件来有效处理,确保系统在遇到新词汇时仍然保持功能和准确性
模型#
在本节中,我们全面回顾了用于音乐检索的音频-文本联合嵌入模型的最新进展。我们考察了这些模型如何从简单的词嵌入方法演变为利用预训练语言模型和 contrastive learning(对比学习)的更深层架构。此外,我们讨论了实用的设计选择和实现技巧,这些可以帮助研究人员和从业者构建稳健的音频-文本联合嵌入系统。
音频-标签联合嵌入#
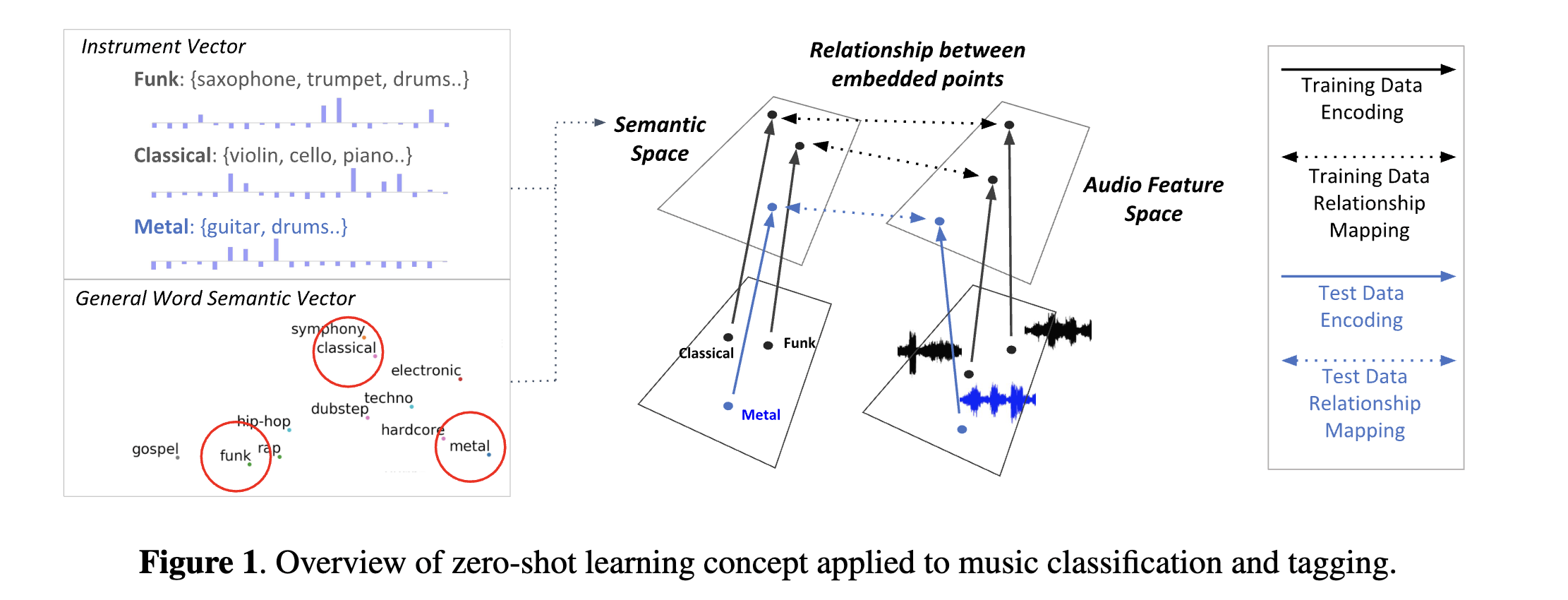
首个引入 ISMIR 社区的重要音频-文本联合嵌入工作由 [CLPN19] 提出。他们的研究展示了预训练词嵌入(特别是 GloVe(Global Vectors for Word Representation))在零样本音乐标注和检索场景中的有效性。这种方法使模型能够理解和处理训练期间从未见过的音乐属性。
在此基础上,[WON+21] 通过纳入协同过滤嵌入扩展了纯音频分析的范围。这一创新使模型能够同时捕获声学属性(音乐如何听起来)和文化方面(人们如何与音乐互动和感知音乐)。[WON+21] 和 [DLJN24] 的进一步研究解决了通用词嵌入的一个关键限制——缺乏音乐特定的上下文。他们开发了专门针对音乐领域词汇和概念训练的音频-文本联合嵌入,从而获得了更准确的音乐相关表示。
然而,这些早期模型在处理更复杂的查询时遇到了显著的限制。具体来说,它们在处理多属性查询(例如,”happy, energetic, rock”)或复杂的句子级查询(例如,”a song that reminds me of a sunny day at the beach”)时表现不佳。这一限制源于它们对静态词嵌入的依赖,静态词嵌入为每个词分配固定的向量表示,与上下文无关。与更高级的语言模型不同,这些嵌入无法根据周围的上下文标记来捕获词汇的不同含义。因此,利用这些模型的研究主要局限于简单的标签级检索场景,即查询由单个词或简单短语组成。
音频-句子联合嵌入#
为了更好地处理多属性语义查询,研究人员将注意力从词嵌入转向了双向 Transformer 编码器 [DCLT18] [Liu19]。这些 Transformer 模型相比静态词嵌入具有以下几个关键优势:
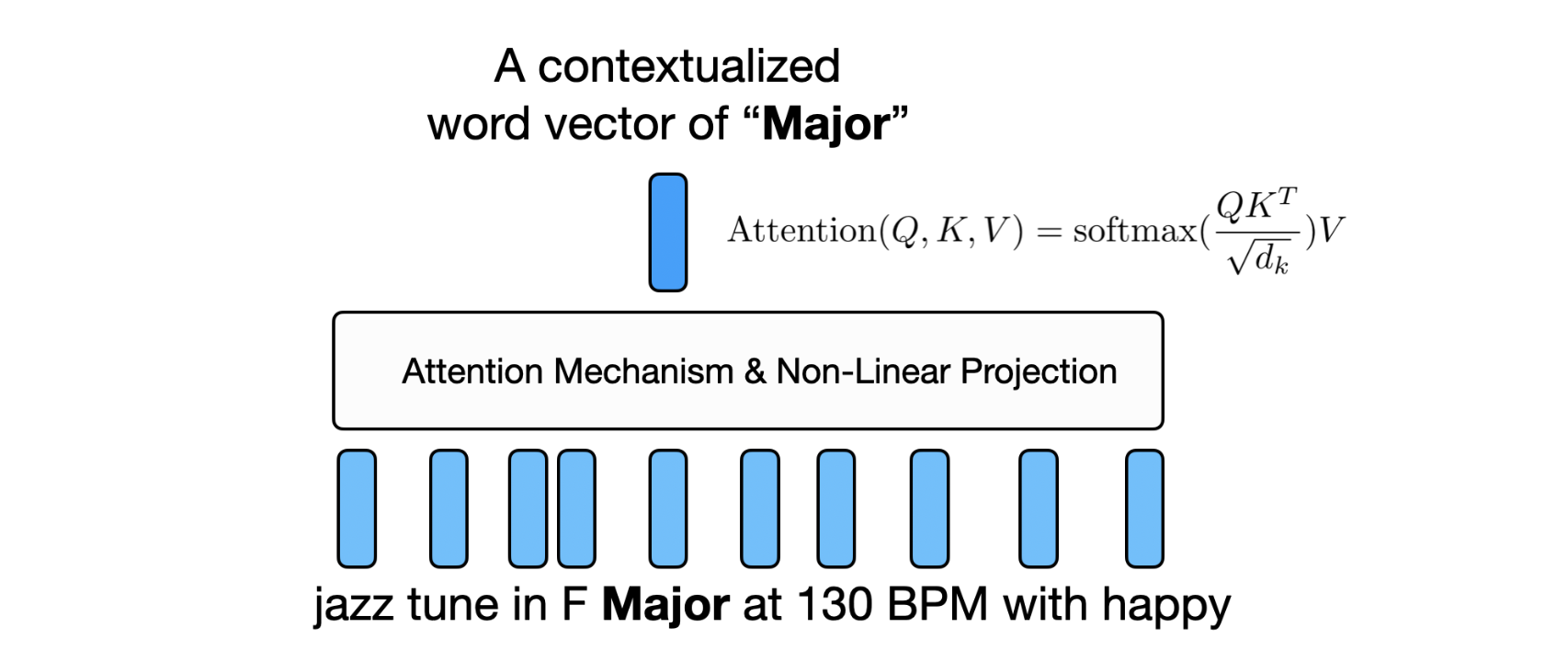
上下文化词表示(Contextualized Word Representations):与为每个词分配固定向量的静态词嵌入不同,Transformer 根据周围的上下文生成动态表示。例如,”heavy”这个词在”heavy metal music”和”heavy bass line”中会有不同的表示。
注意力机制(Attention Mechanism):Transformer 中的自注意力层使模型能够权衡不同词汇之间的相对重要性。这对于理解多个属性之间的交互特别有用——例如,区分”soft rock”和”hard rock”。
双向上下文(Bidirectional Context):与使用因果遮蔽只关注前文标记的自回归 Transformer(例如 GPT)不同,BERT 和 RoBERTa 使用无遮蔽的双向自注意力。这使得每个标记能够同时关注序列中的前文和后文标记。例如,在处理”upbeat jazz with smooth saxophone solos”时,”smooth”一词可以同时关注”upbeat jazz”(前文上下文)和”saxophone solos”(后文上下文),从而实现更丰富的上下文理解。这种双向注意力对于音乐查询尤为重要,因为描述性术语的含义通常同时依赖于前后的上下文。
近期的研究工作已经证明了这些基于 Transformer 方法的有效性。[CXZ+22] 使用 MagnaTagATune 数据集评估了 BERT 语言模型嵌入,展示了在处理包含多个流派和乐器标签的查询时的准确性提升。类似地,[DWCN23] 利用 BERT 在 MSD-ECALS dataset 上处理复杂的属性组合,展示了对”electronic, female vocal elements”或”ambient, piano”等音乐描述的更好理解。
这些研究利用现有的多标签标注数据集来训练和评估语言模型理解多属性查询的能力。结果表明,基于 Transformer 的模型不仅能够处理单个属性,还能有效捕获查询中多个音乐特征之间的关系和依赖。
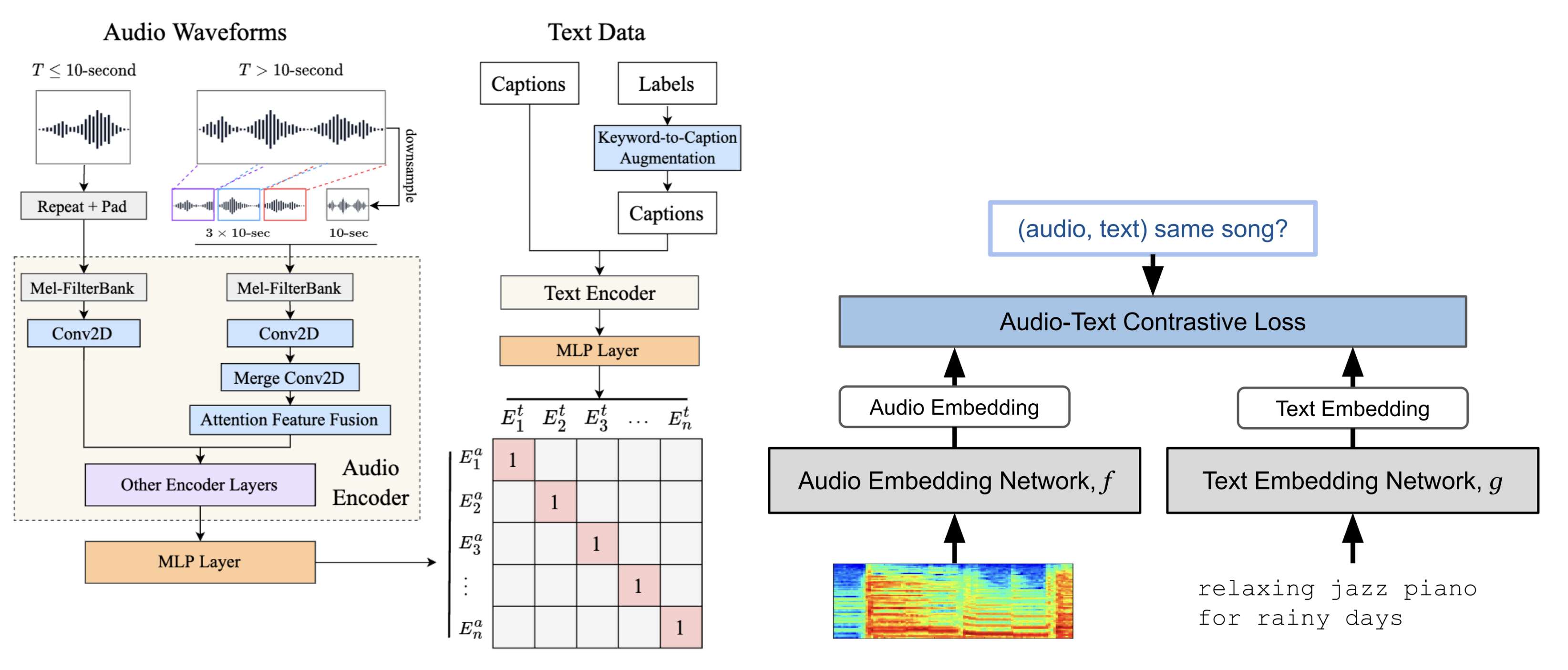
为了处理灵活的自然语言查询,研究人员专注于嘈杂的音频-文本数据集 [HJL+22] 和人工生成的自然语言标注 [MBQF22]。得益于充分的数据集规模和利用大批量优势的 contrastive loss,他们构建了比之前研究具有更强音频-文本关联的联合嵌入模型。[MBQF22]、[HJL+22]、[WCZ+23] 证明了使用大规模音频-文本配对进行 contrastive learning 可以有效学习音乐与自然语言描述之间的语义关系。
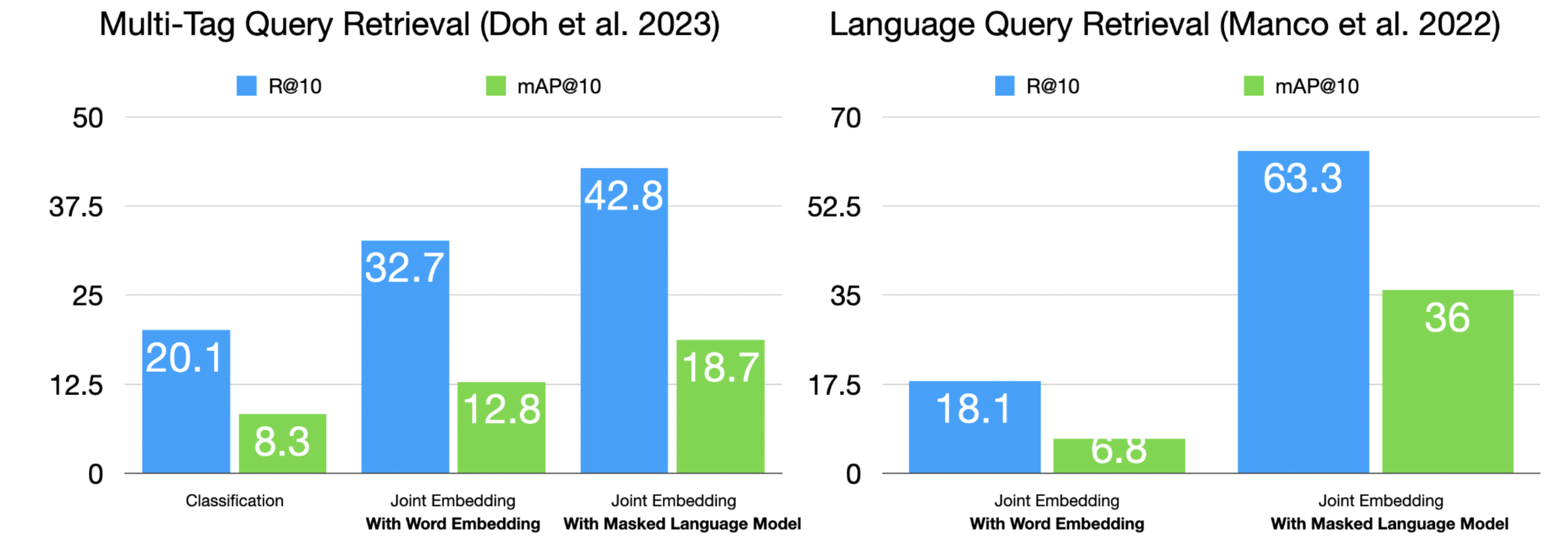
在实践中,预训练语言模型文本编码器在多标签查询检索 [DWCN23] 和自然语言查询检索 [MBQF22] 场景中并未表现出显著的性能提升。
超越语义属性,迈向相似性查询处理#
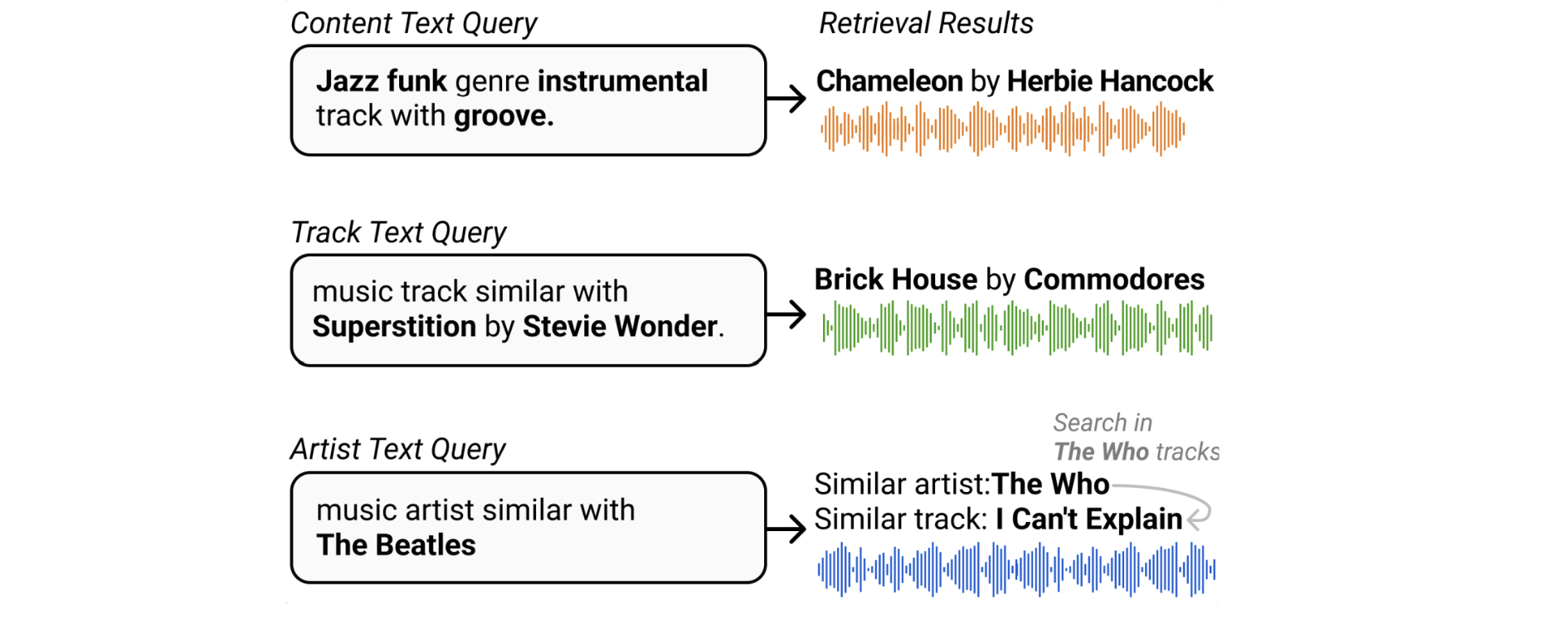
近期的研究探索了将联合嵌入模型扩展到语义属性查询之外,以处理基于相似性的搜索场景。虽然现有的数据集和模型主要关注流派、情绪、乐器、风格和主题等语义属性,但 [DLJN24] 提出了一种新颖的方法,通过利用丰富的元数据和音乐知识图谱来实现基于相似性的查询。
具体来说,他们构建了一个大规模的音乐知识图谱,捕获歌曲之间的各种关系,例如艺术家相似性(风格相似的艺术家的歌曲)、元数据连接(同一艺术家的歌曲)以及曲目-属性关系。通过在该知识图谱上训练联合嵌入模型,模型学会了理解歌曲与其他音乐实体之间的复杂关系。这使系统能够处理诸如”类似 Hotel California 的歌曲”或”听起来像早期 Beatles 的音乐”这样的查询,方法是将查询和音乐嵌入到一个共享的语义空间中,该空间捕获了这些丰富的关系。这种方法显著扩展了音乐检索系统的能力,实现了更加自然和灵活的搜索体验,更好地匹配了人类思考和关联不同音乐作品的方式。
训练音频-文本联合嵌入模型的技巧#
近期的研究已经确定了几个有效训练音频-文本联合嵌入模型的关键策略,这些策略显著提高了模型的性能和稳健性。一个主要挑战是查询格式的多样性——模型必须理解和处理从简单标签(例如,”rock”、”energetic”)到复杂自然语言描述(例如,”a melancholic piano piece with subtle jazz influences”)的各种查询。此外,模型必须弥合音频特征与文本描述中表达的语义概念之间的语义鸿沟。研究人员已经开发了几种有效的策略来应对这些基本挑战,详述如下。
利用多样化的训练数据源#
使用预训练模型初始化#
应用文本增强技术#
采用策略性负采样#
精心选择语义相似但不同的具有挑战性的负样本
这种方法帮助模型发展在相似音乐概念之间做出细粒度区分的能力
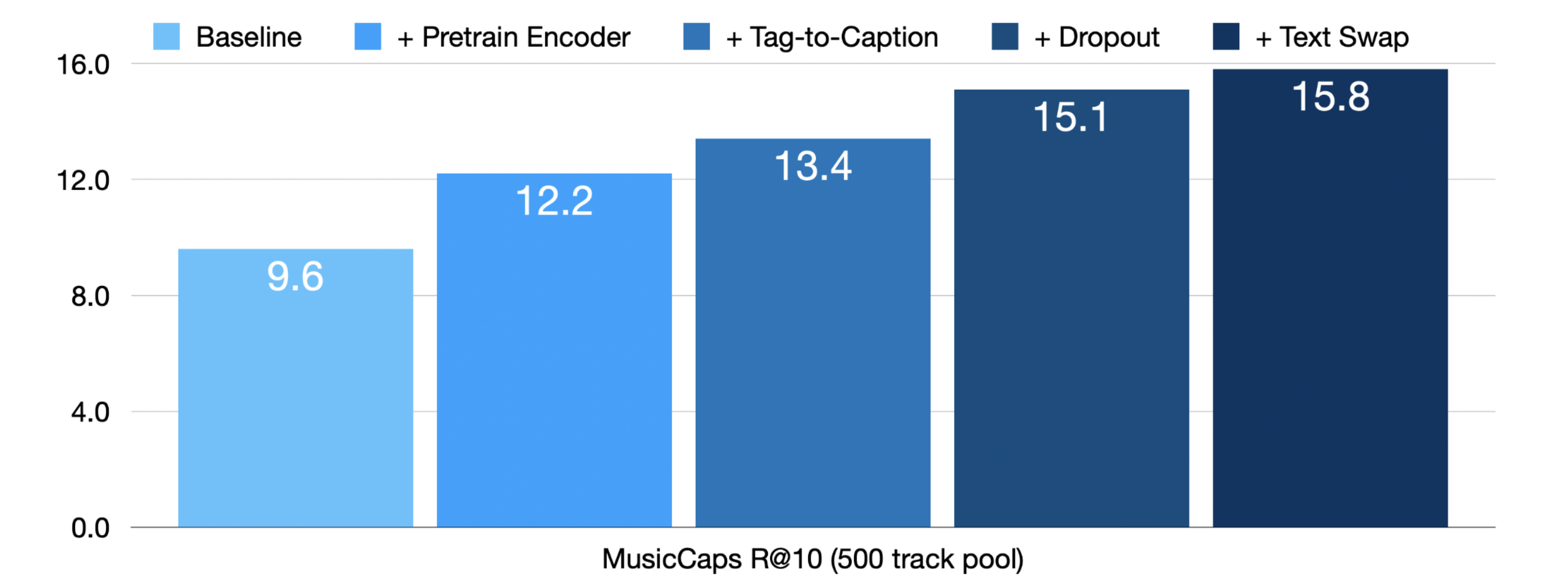
在 [MSN24] 中,这些思路被实现并显著提高了音频-文本联合嵌入模型的检索性能。实验结果显示了显著的改进,在基线模型 [DWCN23] 的基础上应用预训练编码器、标签到描述增强、dropout 和困难负采样(text swap)技术后,R@10 指标从 9.6 提升到了 15.8。这一显著的性能提升证明了组合这些训练策略的有效性。
参考文献#
Tianyu Chen, Yuan Xie, Shuai Zhang, Shaohan Huang, Haoyi Zhou, and Jianxin Li. Learning music sequence representation from text supervision. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 4583–4587. IEEE, 2022.
Jeong Choi, Jongpil Lee, Jiyoung Park, and Juhan Nam. Zero-shot learning for audio-based music classification and tagging. In ISMIR. 2019.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
SeungHeon Doh, Jongpil Lee, Dasaem Jeong, and Juhan Nam. Musical word embedding for music tagging and retrieval. arXiv preprint arXiv:2404.13569, 2024.
SeungHeon Doh, Minz Won, Keunwoo Choi, and Juhan Nam. Toward universal text-to-music retrieval. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1–5. IEEE, 2023.
Qingqing Huang, Aren Jansen, Joonseok Lee, Ravi Ganti, Judith Yue Li, and Daniel PW Ellis. Mulan: a joint embedding of music audio and natural language. arXiv preprint arXiv:2208.12415, 2022.
Yinhan Liu. Roberta: a robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
Ilaria Manco, Emmanouil Benetos, Elio Quinton, and György Fazekas. Contrastive audio-language learning for music. arXiv preprint arXiv:2208.12208, 2022.
Ilaria Manco, Justin Salamon, and Oriol Nieto. Augment, drop & swap: improving diversity in llm captions for efficient music-text representation learning. arXiv preprint arXiv:2409.11498, 2024.
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv:1807.03748, 2018.
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, and others. Learning transferable visual models from natural language supervision. In International conference on machine learning, 8748–8763. PMLR, 2021.
Benno Weck, Holger Kirchhoff, Peter Grosche, and Xavier Serra. Wikimute: a web-sourced dataset of semantic descriptions for music audio. In International Conference on Multimedia Modeling, 42–56. Springer, 2024.
Minz Won, Sergio Oramas, Oriol Nieto, Fabien Gouyon, and Xavier Serra. Multimodal metric learning for tag-based music retrieval. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 591–595. IEEE, 2021.
Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. In IEEE International Conference on Audio, Speech and Signal Processing (ICASSP). 2023.